14.4 USDA食品数据库
美国农业部(USDA)制作了一份有关食物营养信息的数据库。Ashley Williams制作了该数据的JSON版(http://ashleyw.co.uk/project/food-nutrient-database)。其中的记录如下所示:
{"id": 21441,"description": "KENTUCKY FRIED CHICKEN, Fried Chicken, EXTRA CRISPY,Wing, meat and skin with breading","tags": ["KFC"],"manufacturer": "Kentucky Fried Chicken","group": "Fast Foods","portions": [{"amount": 1,"unit": "wing, with skin","grams": 68.0},...],"nutrients": [{"value": 20.8,"units": "g","description": "Protein","group": "Composition"},...]}
每种食物都带有若干标识性属性以及两个有关营养成分和分量的列表。这种形式的数据不是很适合分析工作,因此我们需要做一些规整化以使其具有更好用的形式。
从上面列举的那个网址下载并解压数据之后,你可以用任何喜欢的JSON库将其加载到Python中。我用的是Python内置的json模块:
In [154]: import jsonIn [155]: db = json.load(open('datasets/usda_food/database.json'))In [156]: len(db)Out[156]: 6636
db中的每个条目都是一个含有某种食物全部数据的字典。nutrients字段是一个字典列表,其中的每个字典对应一种营养成分:
In [157]: db[0].keys()Out[157]: dict_keys(['id', 'description', 'tags', 'manufacturer', 'group', 'portions', 'nutrients'])In [158]: db[0]['nutrients'][0]Out[158]:{'description': 'Protein','group': 'Composition','units': 'g','value': 25.18}In [159]: nutrients = pd.DataFrame(db[0]['nutrients'])In [160]: nutrients[:7]Out[160]:description group units value0 Protein Composition g 25.181 Total lipid (fat) Composition g 29.202 Carbohydrate, by difference Composition g 3.063 Ash Other g 3.284 Energy Energy kcal 376.005 Water Composition g 39.286 Energy Energy kJ 1573.00
在将字典列表转换为DataFrame时,可以只抽取其中的一部分字段。这里,我们将取出食物的名称、分类、编号以及制造商等信息:
In [161]: info_keys = ['description', 'group', 'id', 'manufacturer']In [162]: info = pd.DataFrame(db, columns=info_keys)In [163]: info[:5]Out[163]:description group id \0 Cheese, caraway Dairy and Egg Products 10081 Cheese, cheddar Dairy and Egg Products 10092 Cheese, edam Dairy and Egg Products 10183 Cheese, feta Dairy and Egg Products 10194 Cheese, mozzarella, part skim milk Dairy and Egg Products 1028manufacturer01234In [164]: info.info()<class 'pandas.core.frame.DataFrame'>RangeIndex: 6636 entries, 0 to 6635Data columns (total 4 columns):description 6636 non-null objectgroup 6636 non-null objectid 6636 non-null int64manufacturer 5195 non-null objectdtypes: int64(1), object(3)memory usage: 207.5+ KB
通过value_counts,你可以查看食物类别的分布情况:
In [165]: pd.value_counts(info.group)[:10]Out[165]:Vegetables and Vegetable Products 812Beef Products 618Baked Products 496Breakfast Cereals 403Fast Foods 365Legumes and Legume Products 365Lamb, Veal, and Game Products 345Sweets 341Pork Products 328Fruits and Fruit Juices 328Name: group, dtype: int64
现在,为了对全部营养数据做一些分析,最简单的办法是将所有食物的营养成分整合到一个大表中。我们分几个步骤来实现该目的。首先,将各食物的营养成分列表转换为一个DataFrame,并添加一个表示编号的列,然后将该DataFrame添加到一个列表中。最后通过concat将这些东西连接起来就可以了:
顺利的话,nutrients的结果是:
In [167]: nutrientsOut[167]:description group units value id0 Protein Composition g 25.180 10081 Total lipid (fat) Composition g 29.200 10082 Carbohydrate, by difference Composition g 3.060 10083 Ash Other g 3.280 10084 Energy Energy kcal 376.000 1008... ... ...... ... ...389350 Vitamin B-12, added Vitamins mcg 0.000 43546389351 Cholesterol Other mg 0.000 43546389352 Fatty acids, total saturated Other g 0.072 43546389353 Fatty acids, total monounsaturated Other g 0.028 43546389354 Fatty acids, total polyunsaturated Other g 0.041 43546[389355 rows x 5 columns]
我发现这个DataFrame中无论如何都会有一些重复项,所以直接丢弃就可以了:
In [168]: nutrients.duplicated().sum() # number of duplicatesOut[168]: 14179In [169]: nutrients = nutrients.drop_duplicates()
由于两个DataFrame对象中都有”group”和”description”,所以为了明确到底谁是谁,我们需要对它们进行重命名:
In [170]: col_mapping = {'description' : 'food',.....: 'group' : 'fgroup'}In [171]: info = info.rename(columns=col_mapping, copy=False)In [172]: info.info()<class 'pandas.core.frame.DataFrame'>RangeIndex: 6636 entries, 0 to 6635Data columns (total 4 columns):food 6636 non-null objectfgroup 6636 non-null objectid 6636 non-null int64manufacturer 5195 non-null objectdtypes: int64(1), object(3)memory usage: 207.5+ KBIn [173]: col_mapping = {'description' : 'nutrient',.....: 'group' : 'nutgroup'}In [174]: nutrients = nutrients.rename(columns=col_mapping, copy=False)In [175]: nutrientsOut[175]:nutrient nutgroup units value id0 Protein Composition g 25.180 10081 Total lipid (fat) Composition g 29.200 10082 Carbohydrate, by difference Composition g 3.060 10083 Ash Other g 3.280 10084 Energy Energy kcal 376.000 1008... ... ... ... ... ...389350 Vitamin B-12, added Vitamins mcg 0.000 43546389351 Cholesterol Other mg 0.000 43546389352 Fatty acids, total saturated Other g 0.072 43546389353 Fatty acids, total monounsaturated Other g 0.028 43546389354 Fatty acids, total polyunsaturated Other g 0.041 43546[375176 rows x 5 columns]
做完这些,就可以将info跟nutrients合并起来:
In [176]: ndata = pd.merge(nutrients, info, on='id', how='outer')In [177]: ndata.info()<class 'pandas.core.frame.DataFrame'>Int64Index: 375176 entries, 0 to 375175Data columns (total 8 columns):nutrient 375176 non-null objectnutgroup 375176 non-null objectunits 375176 non-null objectvalue 375176 non-null float64id 375176 non-null int64food 375176 non-null objectfgroup 375176 non-null objectmanufacturer 293054 non-null objectdtypes: float64(1), int64(1), object(6)memory usage: 25.8+ MBIn [178]: ndata.iloc[30000]Out[178]:nutrient Glycinenutgroup Amino Acidsunits gvalue 0.04id 6158food Soup, tomato bisque, canned, condensedfgroup Soups, Sauces, and GraviesmanufacturerName: 30000, dtype: object
我们现在可以根据食物分类和营养类型画出一张中位值图(如图14-11所示):
In [180]: result = ndata.groupby(['nutrient', 'fgroup'])['value'].quantile(0.5)In [181]: result['Zinc, Zn'].sort_values().plot(kind='barh')
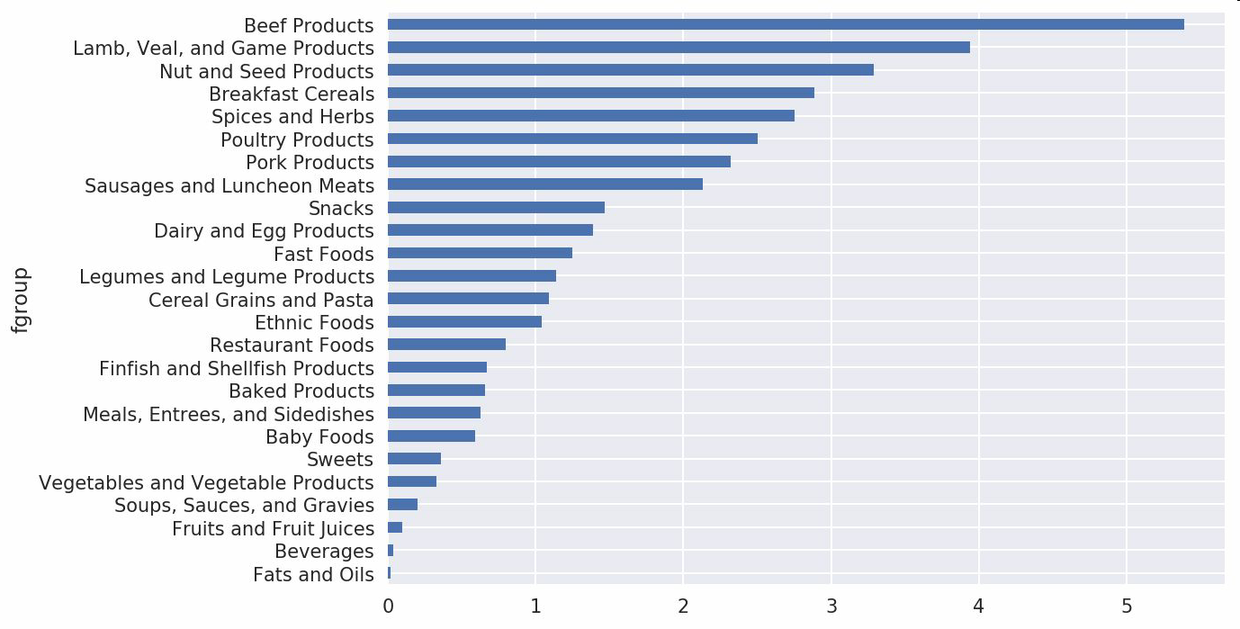
只要稍微动一动脑子,就可以发现各营养成分最为丰富的食物是什么了:
by_nutrient = ndata.groupby(['nutgroup', 'nutrient'])get_maximum = lambda x: x.loc[x.value.idxmax()]get_minimum = lambda x: x.loc[x.value.idxmin()]max_foods = by_nutrient.apply(get_maximum)[['value', 'food']]# make the food a little smallermax_foods.food = max_foods.food.str[:50]
由于得到的DataFrame很大,所以不方便在书里面全部打印出来。这里只给出”Amino Acids”营养分组:
In [183]: max_foods.loc['Amino Acids']['food']Out[183]:nutrientAlanine Gelatins, dry powder, unsweetenedArginine Seeds, sesame flour, low-fatAspartic acid Soy protein isolateCystine Seeds, cottonseed flour, low fat (glandless)Glutamic acid Soy protein isolate...Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...Tryptophan Sea lion, Steller, meat with fat (Alaska Native)Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...Name: food, Length: 19, dtype: object
