- 函数生命周期
- 函数部署流水线
- 函数操作
- 函数版本控制和别名
- 事件源到函数关联
- 事件源
- 函数要求
- 工作流相关要求
- 函数调用类型
函数生命周期
本节描述函数生命周期及如何使用 Serverless 框架/运行时来管理函数生命周期。
函数部署流水线
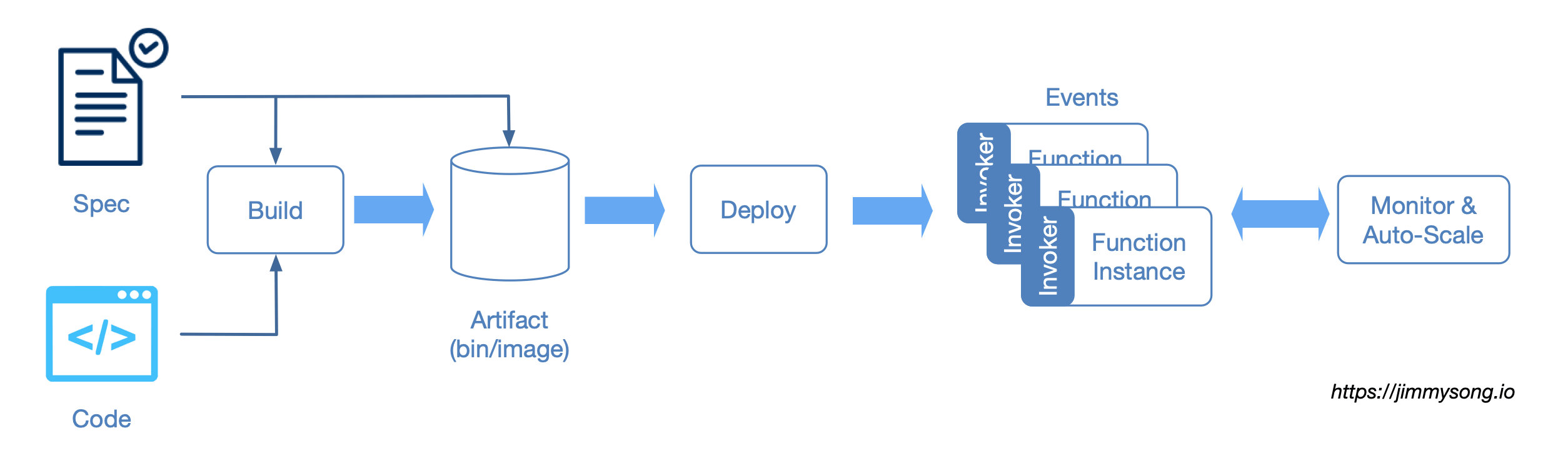
函数的生命周期始于编写代码并提供规范和元数据(请参见下面的函数定义),“builder” 实体将获取代码和规范,进行编译,然后将其转换为工件(代码二进制文件、程序包或容器、镜像)。然后将工件部署到具有控制器实体的集群上,该控制器实体负责根据事件的流量和/或实例上的负载来扩展函数实例的数量。
函数操作
Serverless 框架使用以下动作(Action)控制函数的生命周期:
- 创建:创建新函数,包括其规格(spec)和代码
- 发布:创建可以在集群上部署的函数的新版本
- 更新别名/标签(版本):更新版本别名
- 执行/调用:不通过事件源调用特定版本
- 事件源关联:将函数的特定版本与事件源连接
- 获取:返回函数元数据和规格
- 更新:修改函数的最新版本
- 删除:删除函数,可以删除特定版本或所有版本的函数
- 列表:显示函数及其元数据的列表
- 获取统计信息:返回有关函数运行时使用情况的统计信息
- 获取日志:返回函数生成的日志
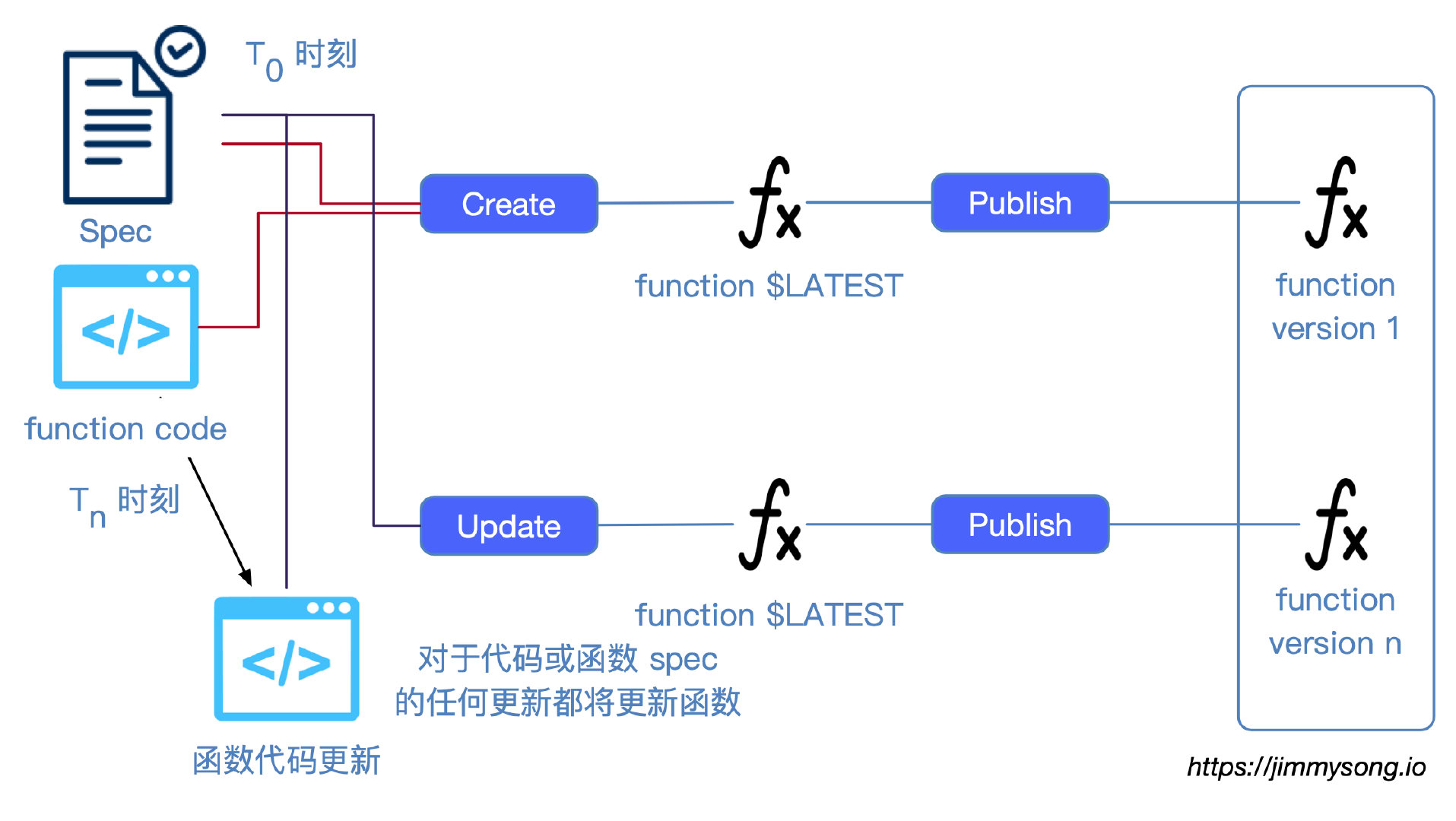
创建函数时需要提供函数的元数据(如稍后在函数规范中所述),创建的函数可能会被编译和发布。稍后可以启动(start)、禁用(disable)和启用(enable)函数。函数部署需要能够支持以下用例:
- 事件流式传输,在这种情况下,可能总是有事件在队列中,但是可能需要通过明确的请求来暂停/恢复处理。
- 热启动(Warm Startup):函数随时都有最少实例数量,由于函数已部署并准备为事件提供服务,因此当收到“第一个”事件时可以热启动(与冷启动相反, 通过“传入”事件在第一次调用时部署函数)。
用户可以发布函数,这将创建一个新版本(“latest” 版本的副本),该发布的版本可能被标记/标签(tag/label)或具有别名(aliases),请参见下文。
用户可能想要直接执行/调用函数(绕过事件源或 API 网关)以进行调试和开发。用户可以指定调用参数,例如所需的版本、同步/异步操作、详细(Verbosity)程度等。
用户可能希望获取函数统计信息(例如,调用次数、平均运行时间、平均延迟、失败、重试等),统计信息可以是当前指标值或值的时间序列(例如,存储在 Prometheus 或云提供商设施中、例如 AWS Cloud Watch)。
用户可能想检索函数日志数据。这可以通过严重性级别和/或时间范围和/或内容来过滤。日志数据是按函数列出的,其中包括以下事件:函数的创建和删除、显式错误、警告或调试消息,以及函数的 Stdout 或 Stderr。最好是每次调用都具有一条日志条目,或者将日志条目与特定调用相关联(以简化对函数执行流的跟踪)。
函数版本控制和别名
一个函数可能具有多个版本,使用户能够运行不同级别的代码,例如 beta/production、A/B测试等。使用版本控制时,默认情况下函数版本为 “latest”,“latest” 版本可以进行更新和修改,可能会在每次更改时触发新的构建过程。
如果用户想要冻结一个版本可以使用发布操作,该操作将创建一个具有潜在标签或别名(例如,“ beta”、“production”)的新版本,以配置事件源,事件或 API 调用可以被路由到特定的函数版本。非最新的函数版本是不可变的(它们的代码以及所有或某些函数规范),并且一旦发布就不能更改。函数不能“未发布”,而应将其删除。
请注意,当前的大多数实现都不允许函数 branch/fork(更新旧版本代码),因为这会使实现和用法变得复杂,但是将来可能需要这样做。
当同一函数有多个版本时,用户必须指定要操作的函数版本以及如何在不同版本之间划分事件流量。例如,用户可以决定路由 90% 的事件流量到稳定版本,10% 的流量到 Beta 版(又称“ canary update” )。可以通过指定确切版本或通过指定版本别名来实现。版本别名通常将引用特定的函数版本。
用户创建或更新函数时,它可能会根据变更的性质来驱动新的构建和部署。
事件源到函数关联
由于事件源触发事件而调用函数。函数和事件源之间存在一个 n:m 映射。每个事件源都可以用于调用多个函数,而一个函数可以由多个事件源触发。事件源可以映射到函数的特定版本或函数的别名,后者提供了一种用于更改函数并部署新版本的方法,而无需更改事件关联。事件源还可以定义为使用同一函数的不同版本,并定义应为每个函数分配多少流量。
创建函数后或稍后的某个时间,需要关联事件源,该事件源应触发作为该事件的函数调用。这需要一系列动作(action)和方法(method),例如:
- 创建事件源关联
- 更新事件源关联
- 列出事件源关联
事件源
不同类型的事件源包括:
- 事件和消息传递服务,例如:RabbitMQ、MQTT、SES、SNS、Google Pub / Sub
- 存储服务,例如:S3、DynamoDB、Kinesis、Cognito、Google Cloud Storage,Azure Blob、iguazio V3IO(对象/流/数据库)
- 端点服务,例如:物联网、HTTP网关、移动设备、Alexa、Google Cloud Endpoint
- 配置存储库,例如:Git、CodeCommit
- 使用特定于语言的 SDK 的用户应用程序
- SchEnable 定期调用函数
尽管每个事件提供的数据在不同事件源之间可能会有所不同,但事件结构应该具有通用性,能够封装有关事件源的特定信息(详细信息见事件数据和元数据)。
函数要求
下面的列表根据当前的技术水平描述了函数和 Serverless 运行时应满足的一组通用要求:
- 函数必须与不同事件类的基础实现分离
- 可以从多个事件源调用函数
- 无需为每个调用方法使用不同的函数
- 事件源可以调用多个函数
- 函数可能需要一种与基础平台服务进行持久绑定的机制,可能是跨函数调用。函数的寿命可能很短,但是如果需要在每次调用时都进行引导,那么引导可能会很昂贵,例如在日志记录、连接、安装外部数据源的情况下。
- 同一个应用程序中每个函数可以使用不同的语言编写
- 函数运行时应尽可能减少事件序列化和反序列化的开销(例如,使用本地语言结构或有效的编码方案)
工作流相关要求
- 函数可以作为工作流的一部分被调用,一个函数的结果可以作为另一个函数的触发
- 可以由事件或 “and/or 事件组合”触发函数
- 一个事件可能触发按顺序或并行执行的多个函数
- “and/or 事件组合”可能触发顺序运行、并行运行或分支运行的 m 个函数
- 在工作流的中间,可能会收到不同的事件或函数结果,这将触发分支切换到不同的函数
- 函数的部分或全部结果需要作为输入传递给另一个函数
- 函数可能需要一种与基础平台服务进行持久绑定的机制,这可能是跨函数调用或函数寿命很短
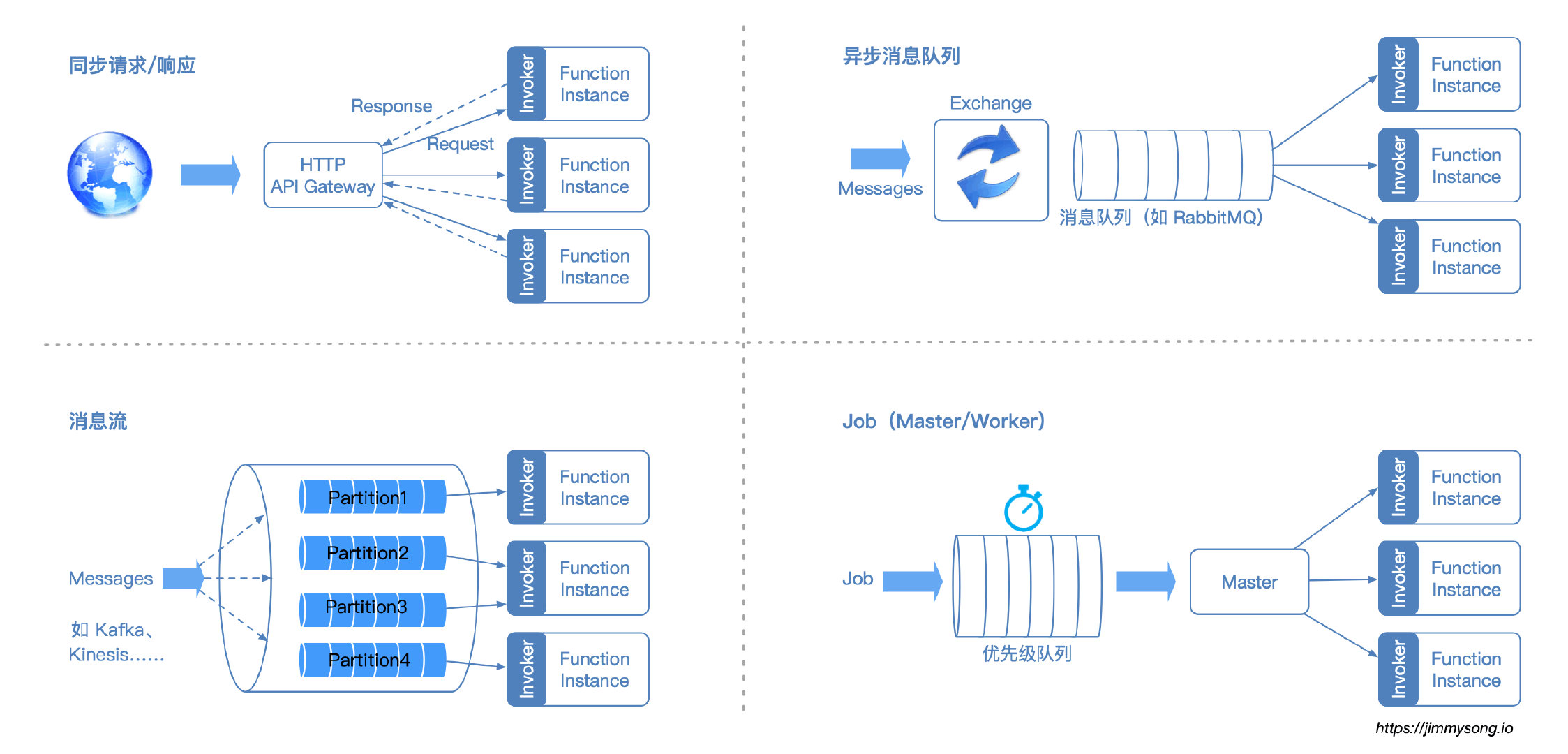
函数调用类型
可以根据不同的用例从不同的事件源调用函数,例如:
- 同步请求(Req/Rep),例如 HTTP 请求、gRPC调用
- 客户端发出请求并等待立即响应。这是一个阻塞调用。
- 异步消息队列请求(Pub/Sub),例如 RabbitMQ、AWS SNS、MQTT、电子邮件,对象(S3)更改、计划事件(如 CRON 作业)
- 消息发布到交换场所并分发给订阅者
- 没有严格的消息顺序。恰好一次(Exactly once)处理
消息/记录流:例如 Kafka、AWS Kinesis、AWS DynamoDB 流、数据库 CDC
- 一组有序的消息/记录(必须按顺序处理)
- 通常,将流分片到多个分区/分片(分片消费者)每个分片分配给一个 worker
- 可以从消息,数据库更新(日志)或文件(例如CSV、Json、Parquet)产生流
- 事件可以推入(Push)到函数运行时或由函数运行时拉取(Pull)
- 批处理作业,例如 ETL 工作、分布式深度学习、HPC 模拟
- 作业被调度或提交到到队列中,并在运行时使用多个并行的函数实例进行处理,每个实例处理工作集(一个任务)的一个或多个部分
- 当所有并行 worker 成功完成所有计算任务时,作业完成