- 数据切分
- 概念
- 后台任务
数据切分
概念
默认情况下,一个集合会被创建在一个随机的分区组中。如果用户希望对该集合进行水平切分,将其划分到其它分区组中,就需要数据切分功能。
数据切分是一种将数据在线从一个分区组转移到另一个分区组的方式。在数据转移的过程中,查询所得的结果集数据会存在暂时的不一致,但是 SequoiaDB 可以保证磁盘中数据的最终一致性。
切分过程示例如下:
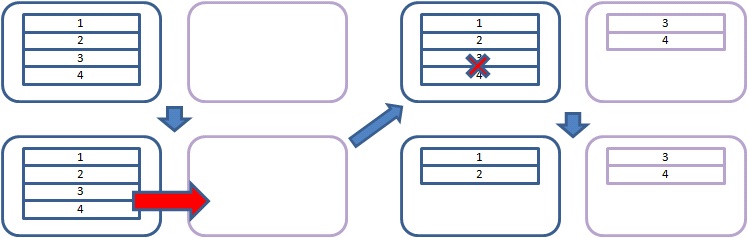
图中左上角为系统的起始状态,4条记录均存放在左侧的节点中。切分时定义由数据3起始,因此数据3与4会被切分至右侧节点。(左下图)
图中右上角为第三状态,数据在两个分区组中同时存在。此刻数据会有暂时的不一致。最终状态切换到右下图,已经迁移成功的数据从原始节点删除,数据最终恢复一致。
Range 分区和 Hash 分区都支持两种切分方式:范围切分和百分比切分。
1.在范围切分时,Range 分区使用精确条件(如字段“a”):
- > db.foo.bar.split( "src", "dst", { a: 10 }, { a: 20 } )
Note:
假设集合foo.bar已经指定为Range分区。
'src'、'dst'分别表示“数据原本所在复制组”、“数据将要切分到的目标复制组”。
数据切分及分区上的数据范围皆遵循左闭右开原则。即:{a:10},{a:20} 代表迁移数据范围为[10, 20)。
2.在范围切分时, Hash 分区使用Partition(分区数)条件:
- > db.foo.bar.split( "src", "dst", { Partition: 10 }, { Partition: 20 } )
Note:
- 假设集合foo.bar已经指定为Hash分区
3.在百分比切分时,Range 分区和 Hash 分区执行的命令没有区别:
- > db.foo.bar.split( "src", "dst", 50 )
后台任务
数据切分属于一个后台任务。
对于数据切分的后台任务拥有几个特有的字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
| SourceName | 字符串 | 源分区所在复制组名。 |
| TargetName | 字符串 | 目标分区所在复制组名。 |
| SourceID | 整数 | 源分区所在复制组 ID。 |
| TargetID | 整数 | 目标分区所在复制组 ID。 |
| SplitValue | 对象 | 数据切分键。 |
数据切分的后台操作分为几个阶段:
- 准备阶段:
在准备阶段中,并不会向编目节点的 SYSCAT.SYSTASKS插入任务记录。该阶段首先向编目节点查询,确保该请求合法,并且向源数据节点组请求得到一条包含分区条件的记录或根据规则生成一条包含分区条件的记录。
- 预备阶段:
在预备阶段中,协调节点将分区条件发送至编目节点。编目节点在SYSCAT.SYSTASKS 集合中插入后台操作记录。
- 运行阶段:
在运行阶段中,协调节点向目标节点发送切分请求,目标节点创建后台任务,从源节点请求数据,并向编目节点上报自身状态。目标节点会在后台任务创建后直接返回给协调节点,并不会长时间阻塞用户会话。
- 清除阶段:
在清除阶段中,目标节点已经从源节点得到所有的数据,因此向编目节点发送清除请求,并在源数据节点进行数据清除操作。
- 完成阶段:
在源节点清除了所有已经迁移的数据后,会向编目节点发送完成消息。编目节点从SYSCAT.SYSTASKS 集合中删除该任务。
