- 用户指南
- 安装 logkit Pro 到机器
- 收集数据
- 获取数据
- 解析数据
- 按grok格式解析
- 转换数据
- 发送数据
- 分发收集器
- 查看收集器运行信息
- 机器管理
- 标签管理
用户指南
安装 logkit Pro 到机器
进入 logkit Pro 官网,点击【机器管理】-> 【添加机器】,进入安装页面,logkit Pro 提供自动录入和手动安装两种方式添加机器。
- 手动安装:点击【复制地址】,就可以获取我们提供的一键式安装脚本。
在安装之前,您可以为机器指定一个标签来统一管理同一个业务下的机器。
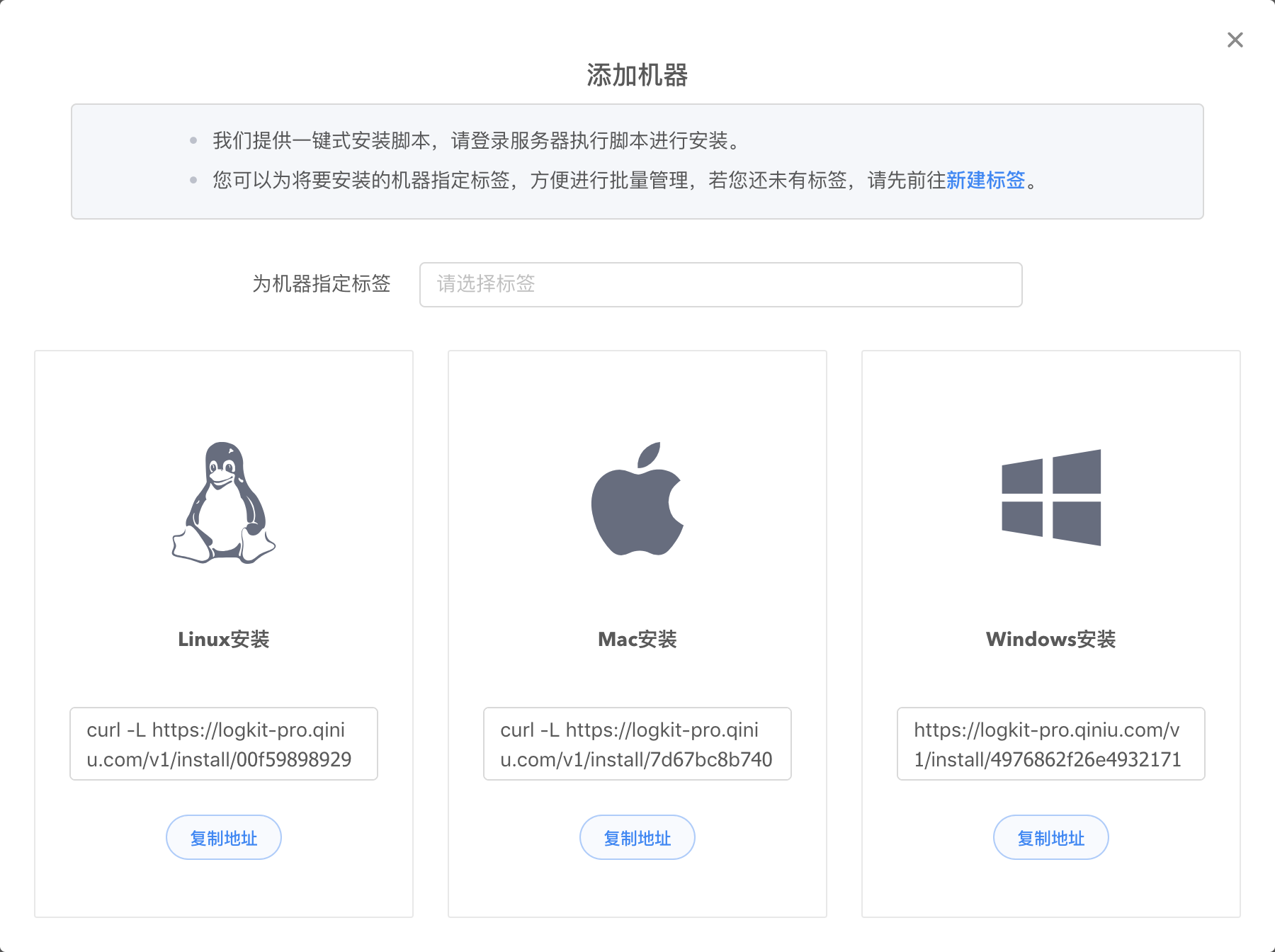
对于linux或mac用户来说,直接在控制台粘贴并执行复制的命令即可。
对于windows用户,将复制的url在浏览器打开,将内容复制到文本文件中,并另存为 logkit.vbs,再双击执行 logkit.vbs 脚本安装。

- 自动录入:输入机器 ip、ssh 端口、用户信息等在服务器上安装 Agent。
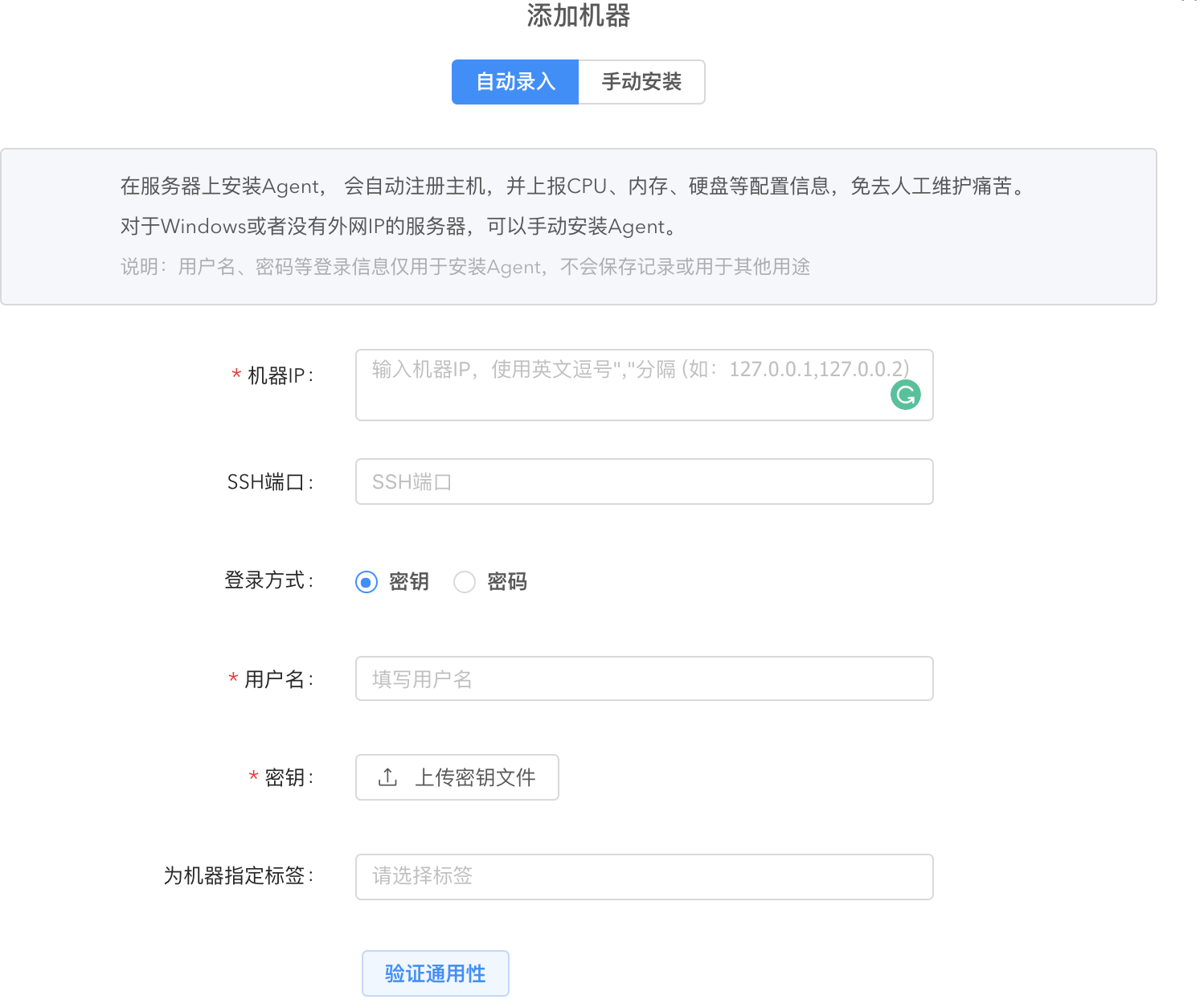
安装好以后您可以在【机器管理】列表看到机器的相关信息,如机器所属标签、机器里的所有收集器、机器地址等,详细信息阅读机器管理。
收集数据
在机器上安装好 logkit Pro 之后就可以开始收集数据。进入数据收集页面,点击添加收集器开始配置收集器。
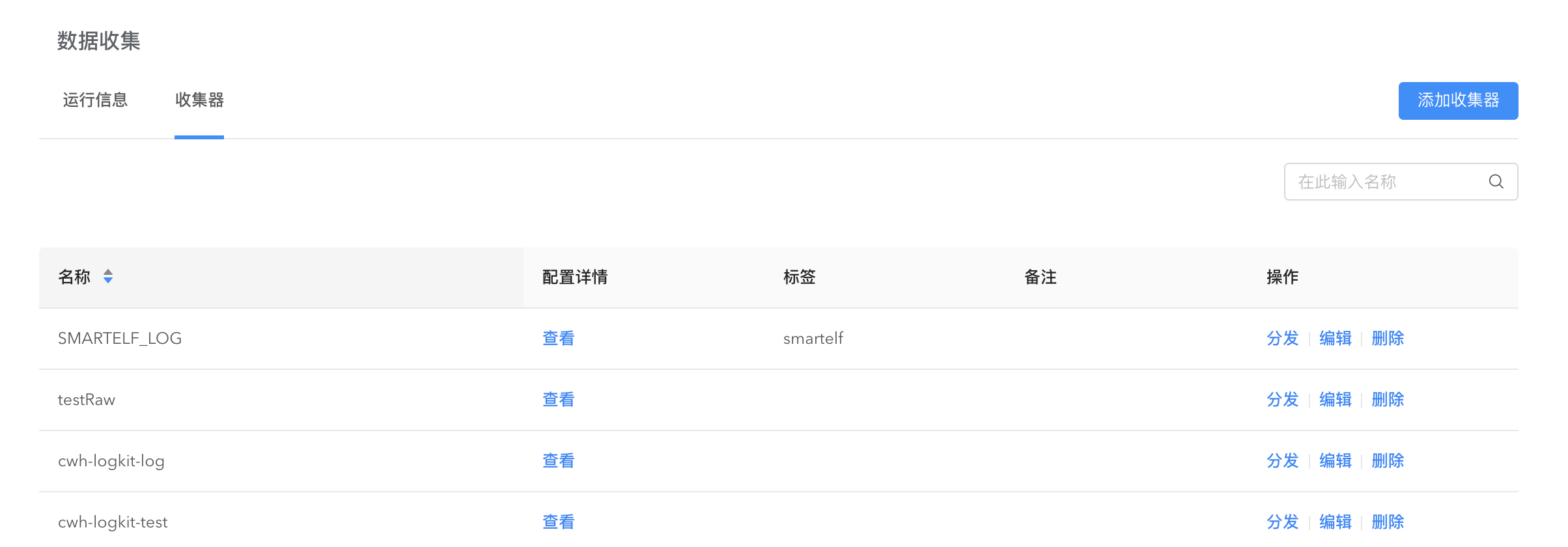
获取数据
第一步是接收数据源,logkit Pro 支持多种数据来源和读取模式,根据需要在左侧列表选取。
填写好配置信息之后,选择您添加的 agent,点击【获取数据】,系统将使用您的配置,让 agent 去获取实际的数据,并且展示样例数据以验证您的配置是否正确。

默认不需要配置高级选项,高级选项保持默认值即可。
logkit Pro 支持的采集数据源
- File: 读取文件中的日志数据,包括 csv 格式的文件,kafka-rest 日志文件, nginx 日志文件等,并支持多种读取模式(fileauto、dir、file、tailx)
- MySQL: 读取 MySQL 中的数据。
- MSSQL: 读取 Microsoft SQL Server中的数据。
- Postgre SQL: 读取 PostgreSQL 中的数据。
- ElasticSearch: 读取 ElasticSearch 中的数据。
- MongoDB: 读取 MongoDB 中的数据。
- Kafka: 读取 Kafka 中的数据。
- Redis: 读取 Redis 中的数据。
- Socket: 读取 tcp\udp\unixsocket 协议中的数据。
- Http: 作为 http 服务端,接受 POST 请求发送过来的数据。
- Script: 支持执行脚本,读取执行结果中的数据。
- Snmp: 主动抓取 Snmp 服务中的数据。
- AWS CloudWatch: 主动抓取 AWS CloudWatch接口中的数据。
- AWS CloudTrail: 主动抓取 AWS CloudTrail中的数据。
关于数据源类型以及高级选项详细介绍,请阅读数据源类型。
解析数据
第二步,根据数据源配置合适解析方式,抽取数据中的字段,转化为结构化数据,充分保障您的配置一定能在实际场景中生效。logkit Pro 支持多种格式的日志解析,按需选取并填写相应的配置信息即可。
按grok格式解析
通过配置 grok pattern 解析,将文本格式的字符串转化为结构化的数据。使用 grok 解析日志内容会使得日志分析更加容易。logkit Pro 提供默认匹配日志的 grok 表达式、grok 划词以及自定义 grok 表达式三种方式进行解析。
- 默认 grok 表达式:
使用系统匹配日志的 grok pattern 来解析您的数据:
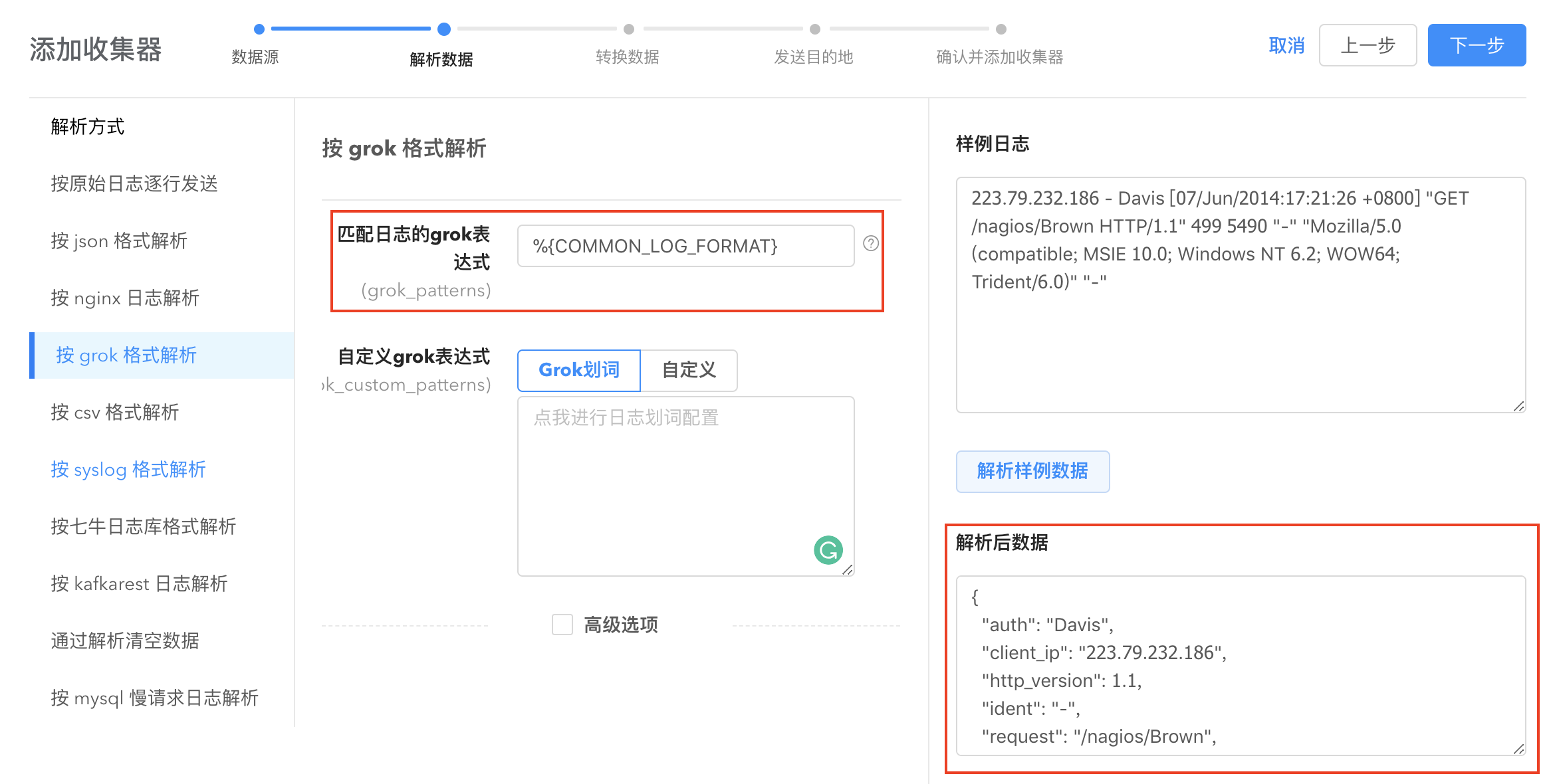
- 如果默认 pattern 解析没法满足您的需求,logkit Pro 支持自定义 grok pattern。
grok划词
通过在数据上划词解析数据:在数据上点选数据内容,系统会自动匹配 grok 变量生成 pattern,字段名、字段类型与 grok 变量均可编辑。通过划词生成的 pattern 以及 划词解析后的数据均可见。
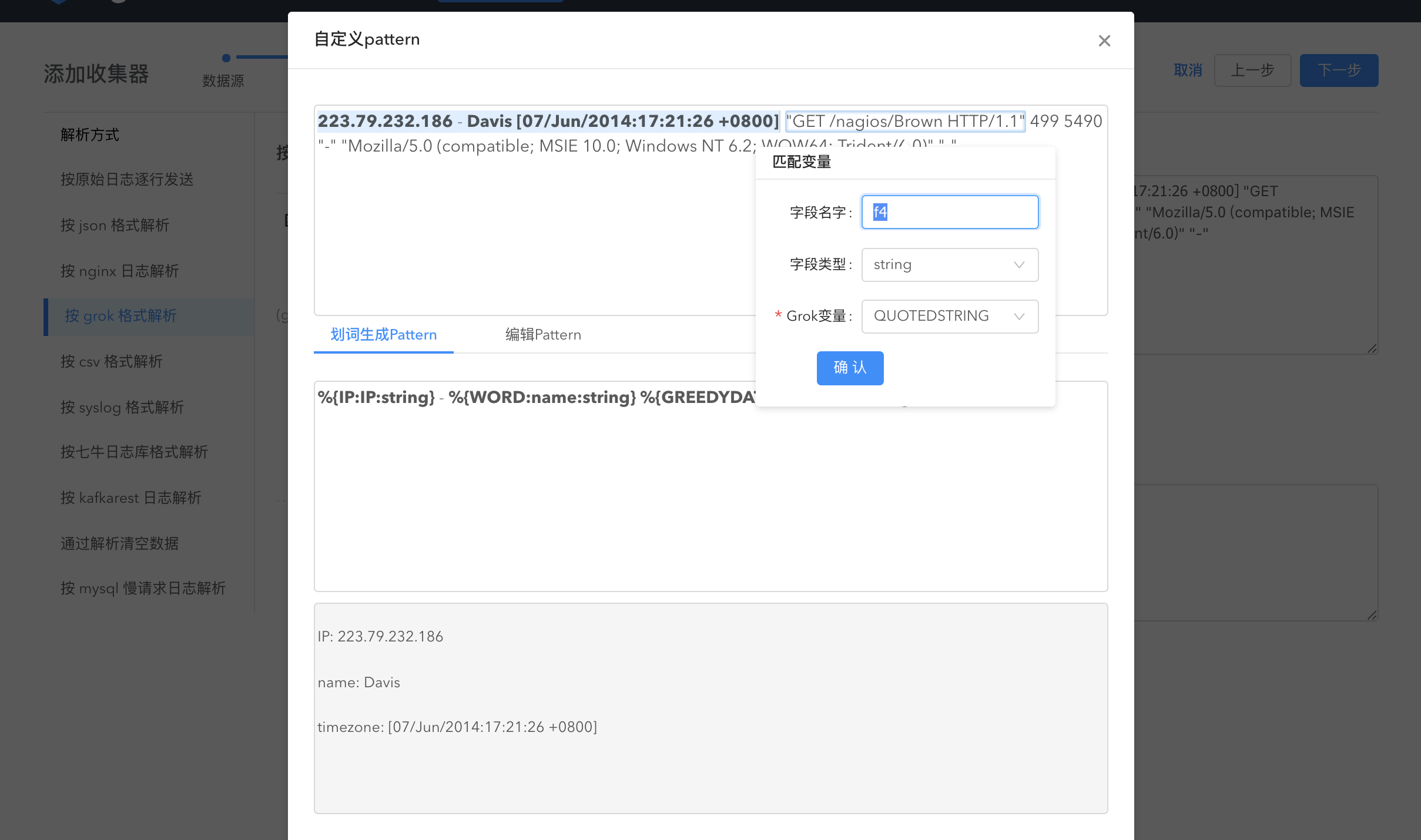
如果部分数据内容无法全部用划词解析,您还可以编辑 pattern。
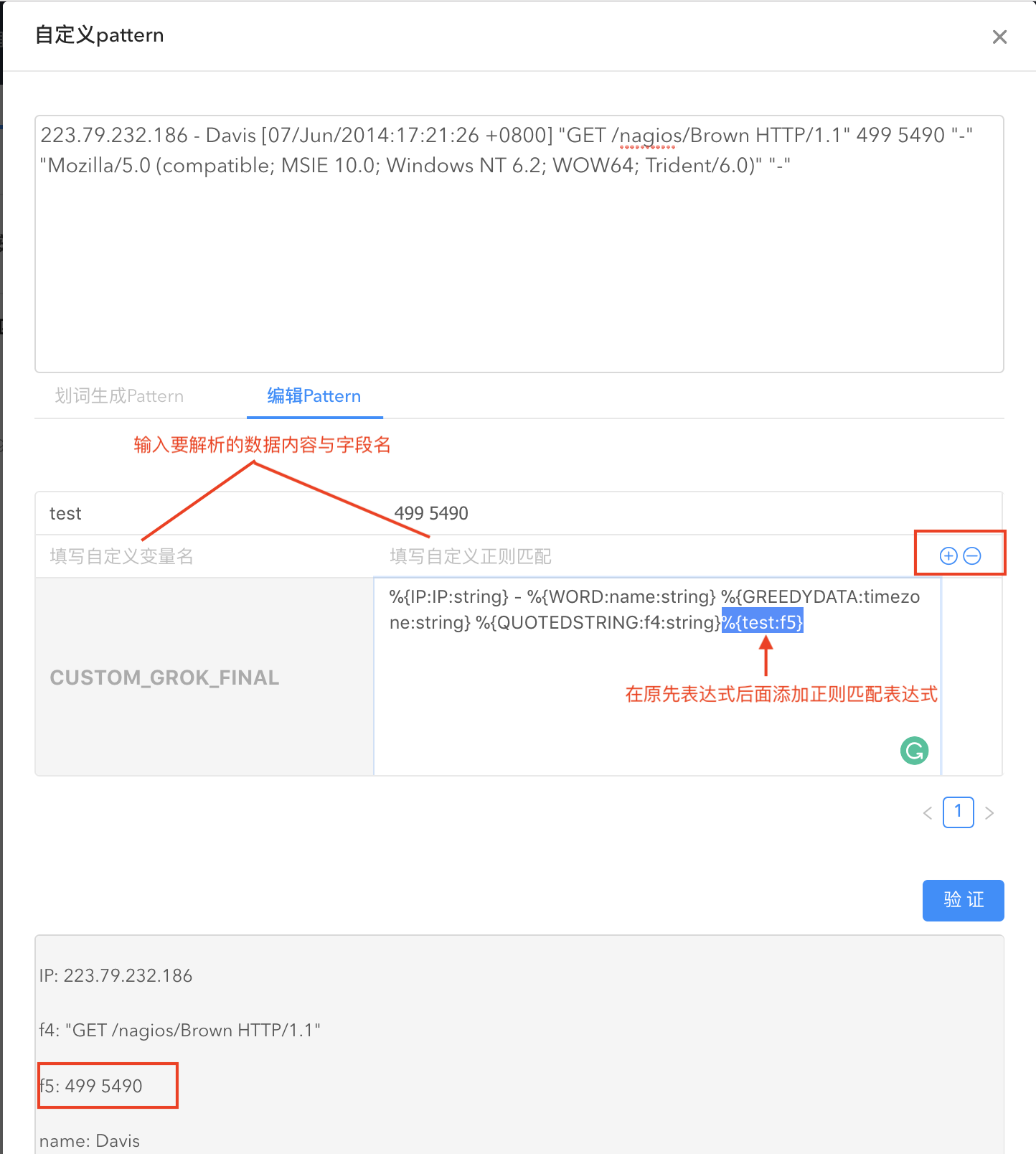
点击验证即查看解析结果。
您也可以直接输入自定义 pattern。
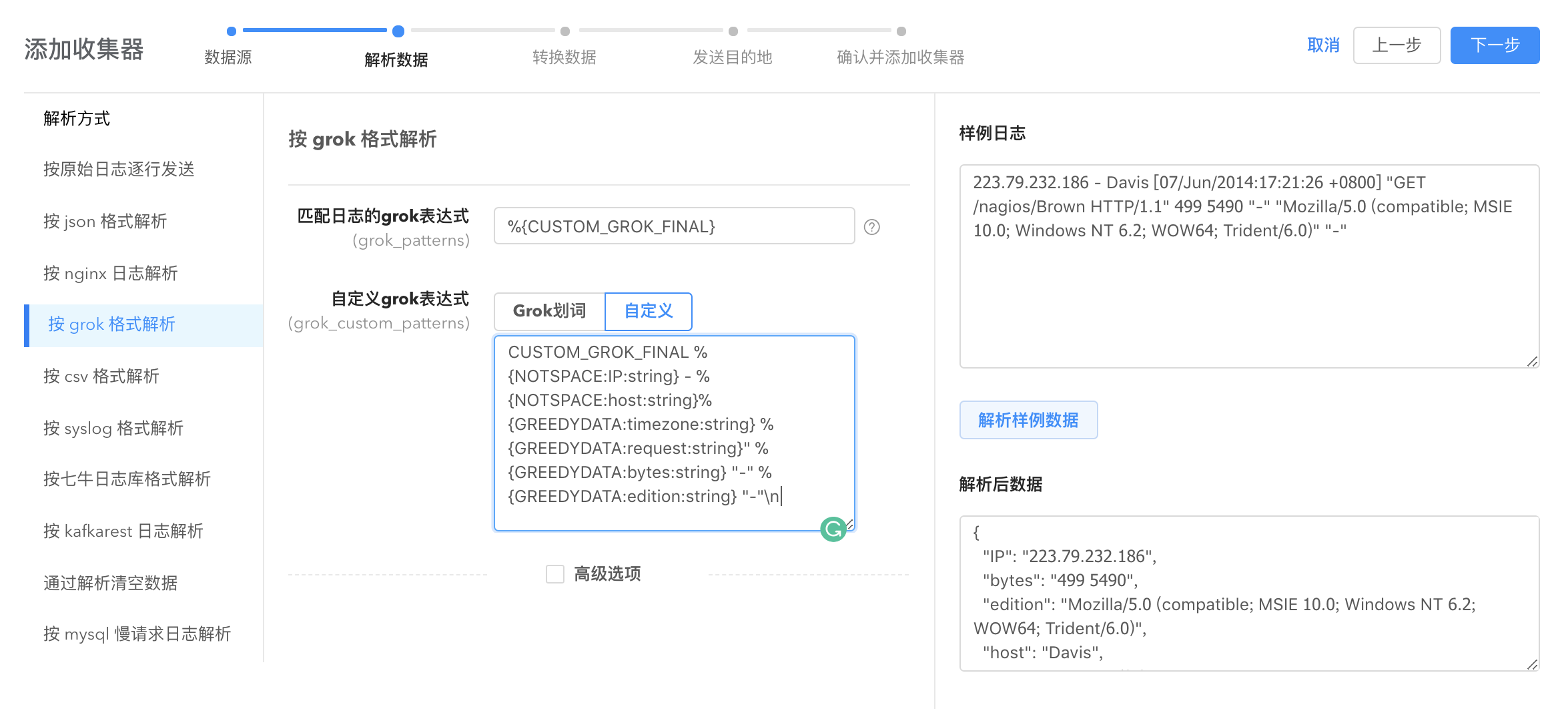
其他解析方式:
按原始日志逐行发送:直接按行读取日志内容。
按 json 格式解析:通过 json 反序列化解析日志内容,无需任何配置,系统根据日志内容自动解析。
按 csv 格式解析:按分隔符解析日志。
按 nginx 日志解析:专门解析 Nginx 日志。仅需指定 nginx 的配置文件地址,即可进行 nginx 日志解析。
按 syslog 格式解析:自动解析系统日志
七牛日志库格式解析: 七牛开源的 golang 日志库日志格式解析
按 kafkarest 日志解析: Kafkarest 日志解析
通过解析清空数据:清空读取的数据
按 mysql man 请求日志解析: mysql 慢请求日志解析
关于其他数据解析方式的详细解说,请阅读数据解析方式。
转换数据
logkit Pro 提供数据转换功能来满足一些更精细的字段解析需求。
在大多数场景下,用 Parser 解析就解决了问题,但是有些场合,用 Parser 来做数据解析可能过于简单,如 json parser。如果数据里面有一部分字段您希望做一些扩展,比如有个 IP 字符串,您希望将其扩展为 IP 对应的区域、城市、省份、运营商等信息,此时您就可以配置一个 Transformer,对 IP 字段进行转换。
再比如,当您希望做一些字符串替换的时候,只针对某个字段做一个字符串替换处理,那就可以配置一个 replace transformer。
- urlparam: 将指定字段的内容按照 url 参数的格式转换为键值对。
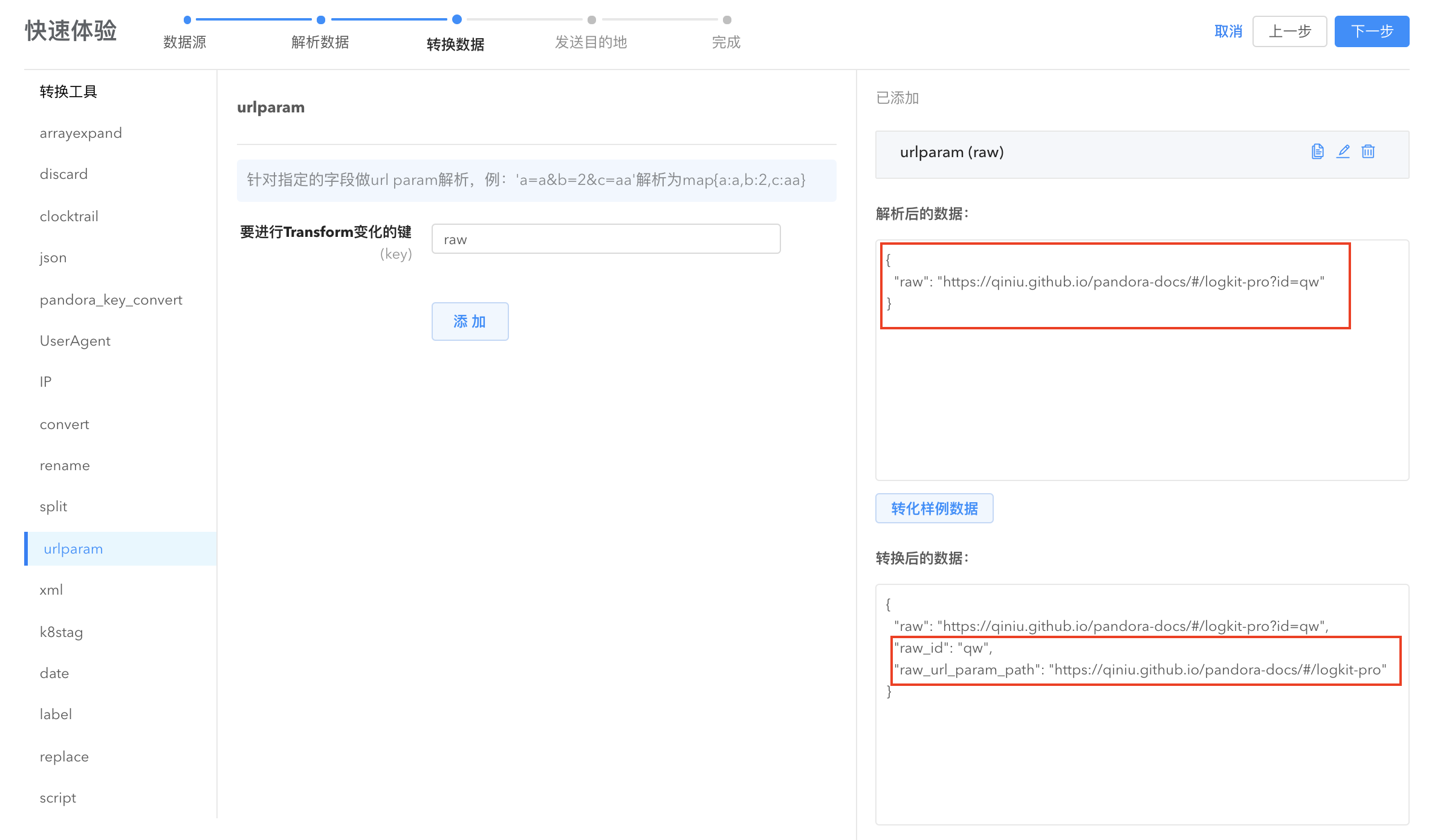
- arrayexpand: 将数组字段展开并转换为键值对。
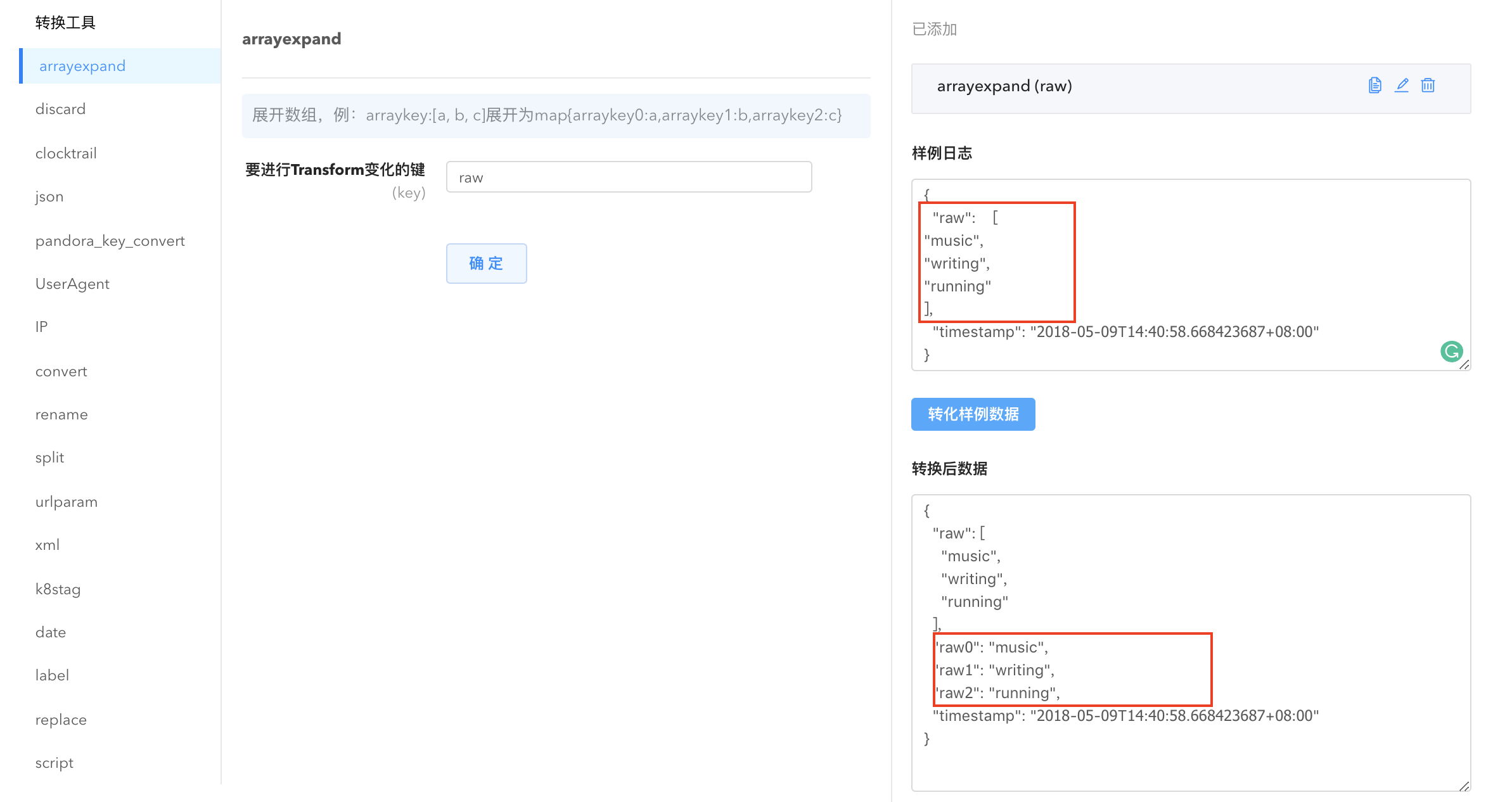
- convert: 转换数据格式。点击
新增转化字段,选择需要转换的字段名,给它指定字段类型即可完成数据格式的转换,也可手动书写 dsl 描述将数据类型转换为指定的格式。
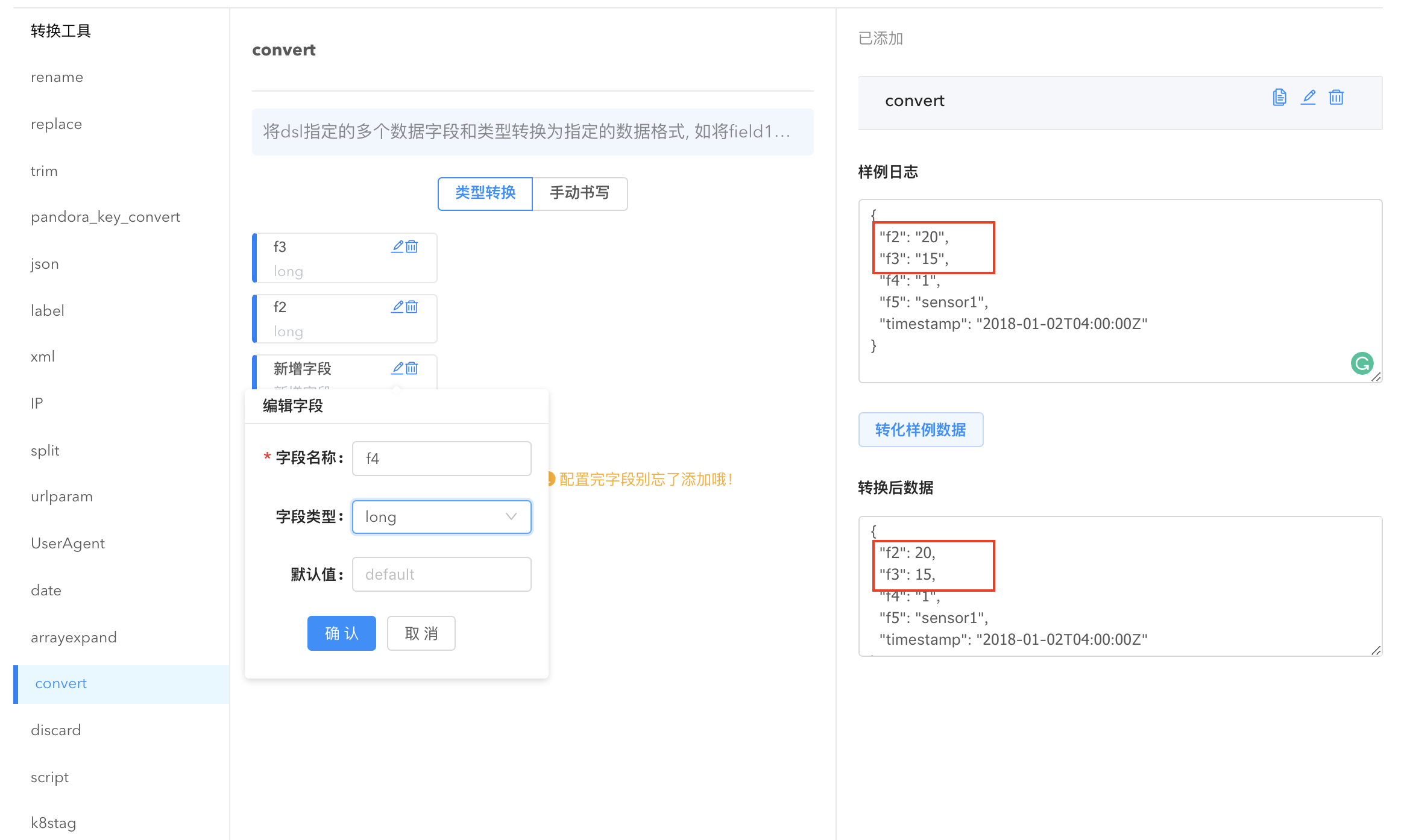
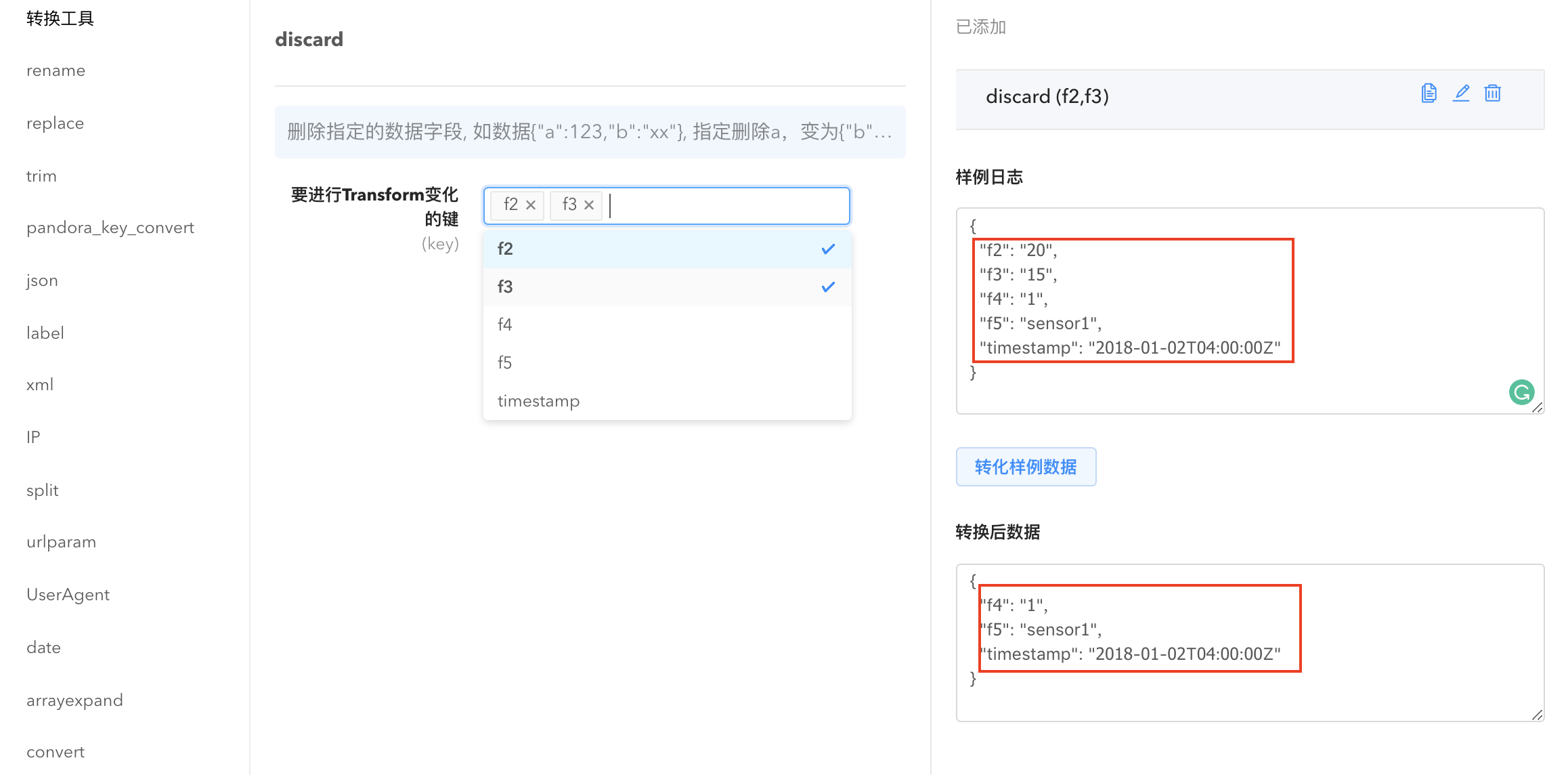
- discard: 将指定字段的数据抛弃,可以同时选择多个字段一键删除。
- date: 将 string/long 数据转换成指定的时间格式, 如 1523878855 变为 2018-04-16T19:40:55+08:00
。或者对时间字段进行时区转换。系统根据用户选择的 key 自动解析。

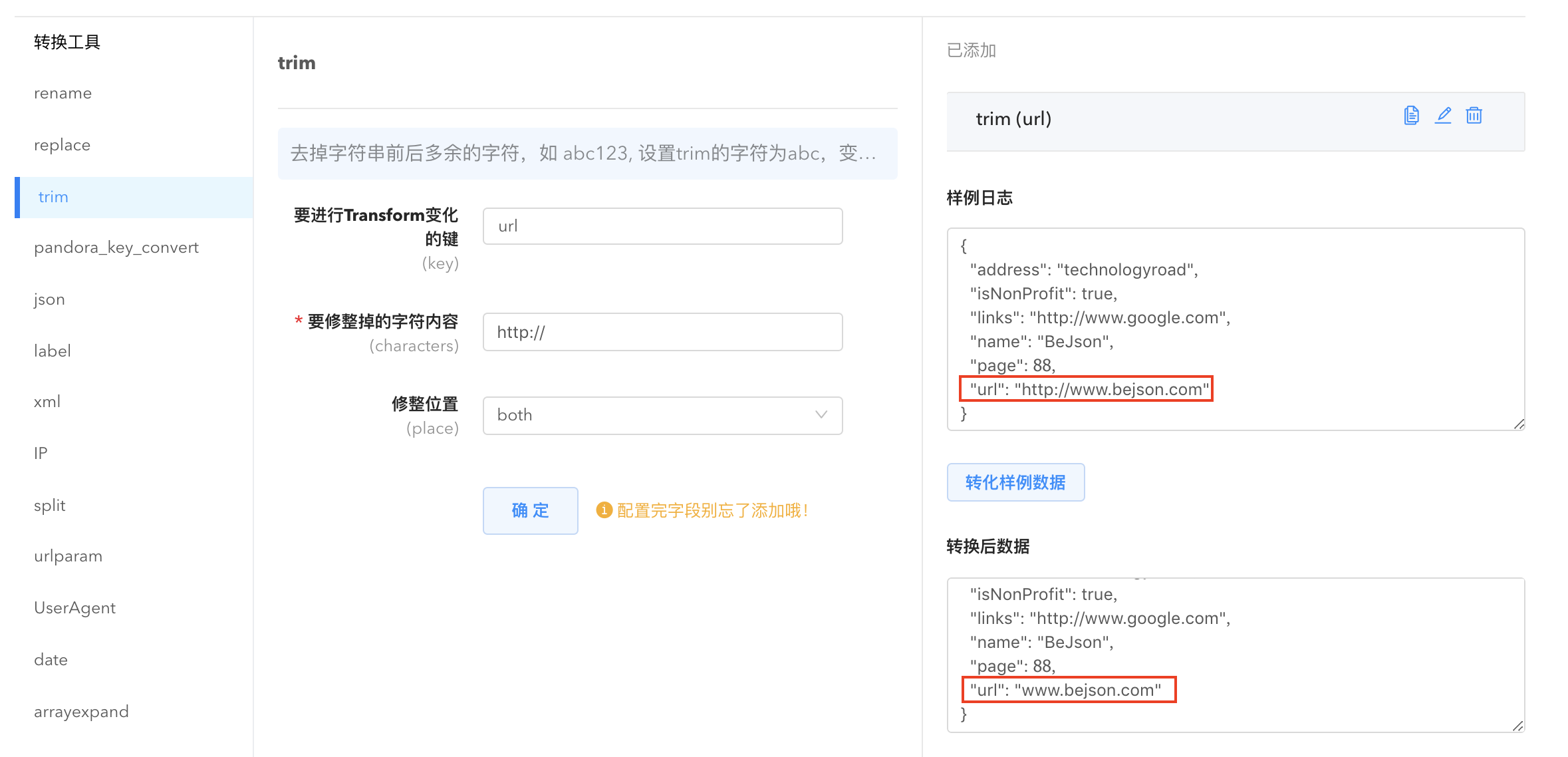
- trim: 去掉字符串多余的字符。
- json: 将一个符合json格式的字符串字段,反序列化为对应结构体类型。

rename: 将字段名称重命名,解决不同下游系统对字段名称中特殊字符不支持的问题。
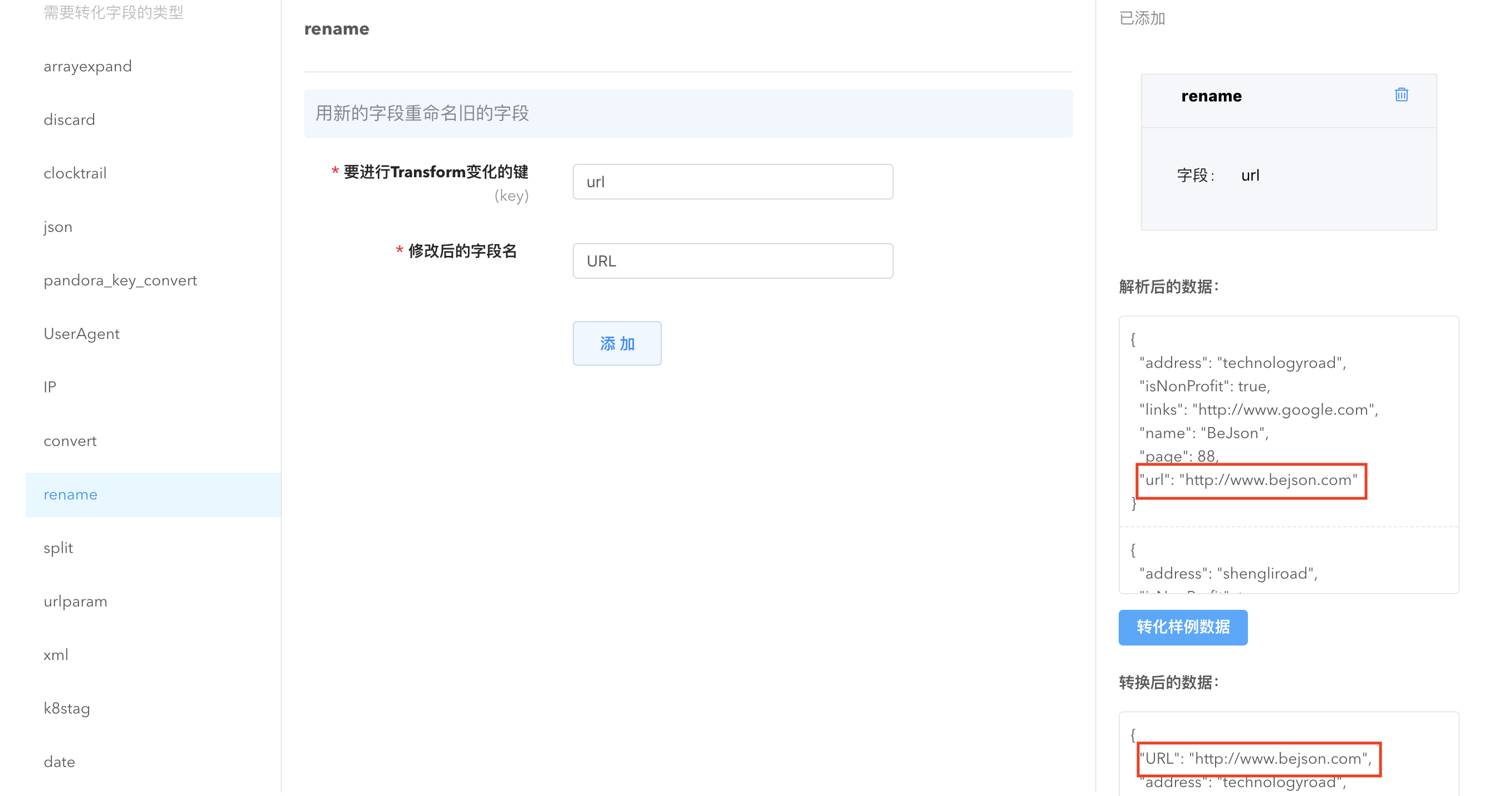
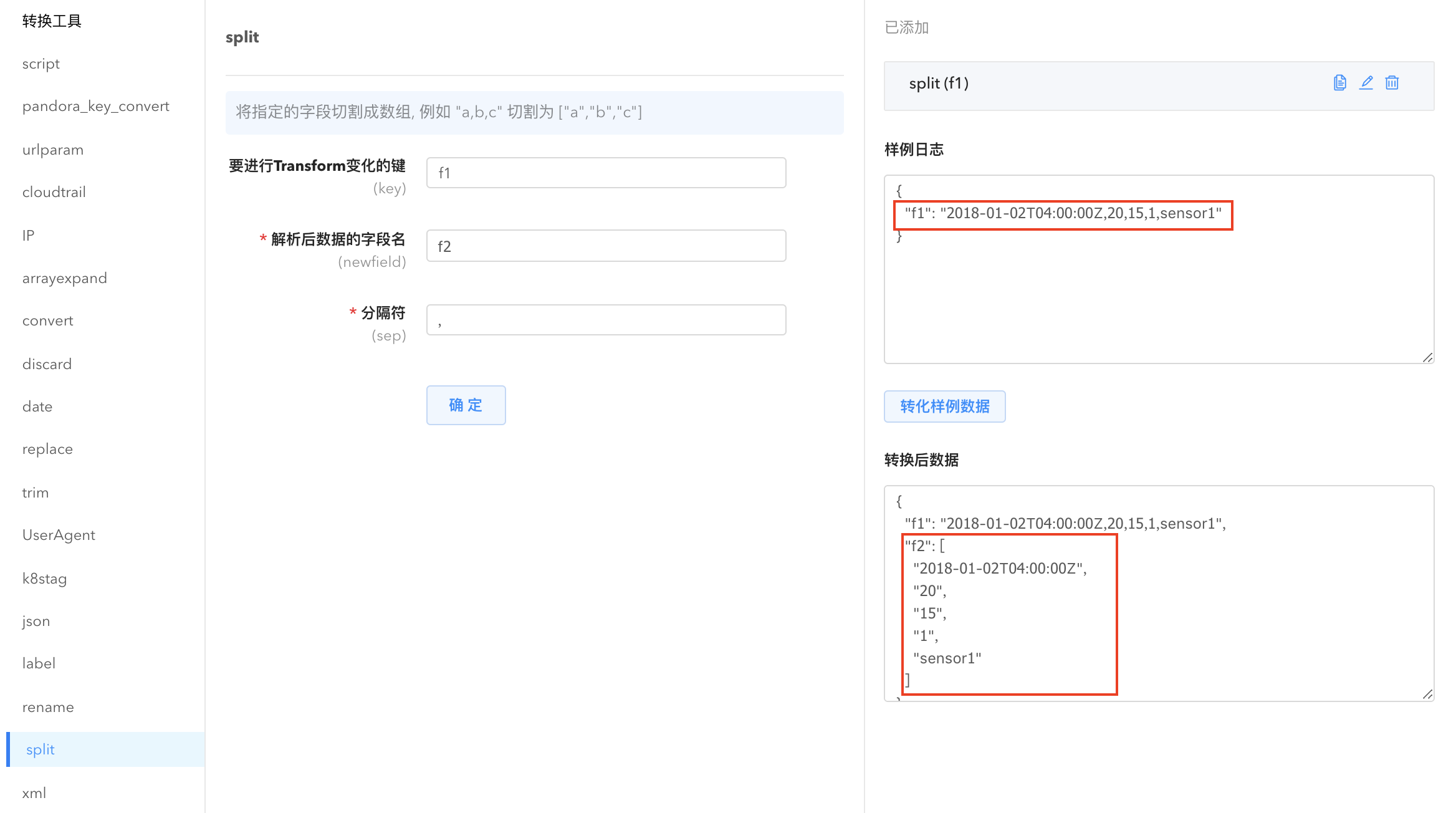
split: 将指定字段的数据切分为字符串数组。
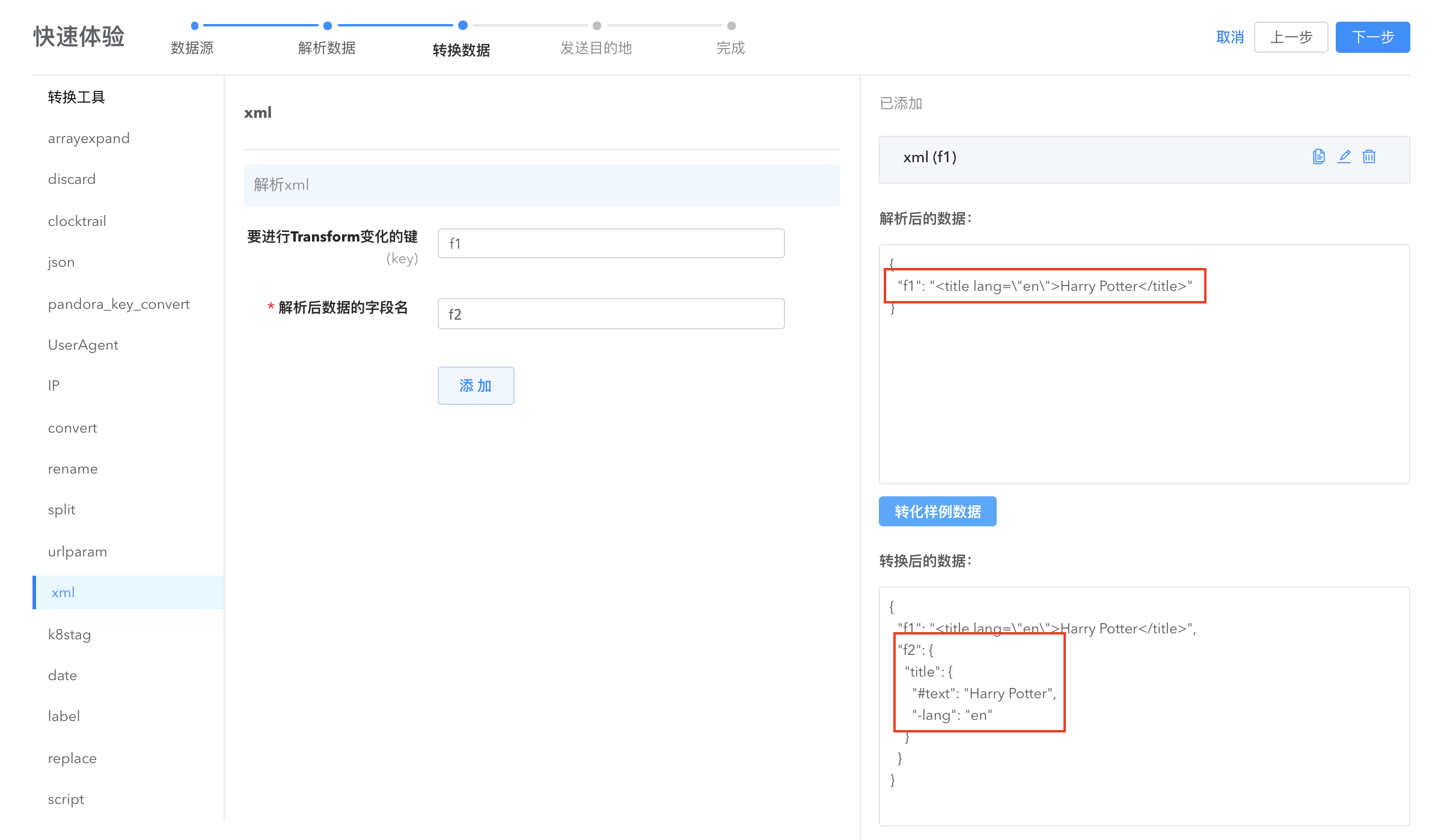
- xml: 将一个符合xml格式的字符串字段,反序列化为对应 map[string]interface{} 结构体类型。
其他字段转换功能:
- script: 执行脚本文件,并将脚本结果加入到数据中。
- pandora_key_convert: 将不符合 Pandora 字段命名规则的 key 字符转化为下划线。
- cloudtrail: 针对 AWS CloudTrail 的数据做格式转换,将 CloudTrail 的 json 格式中的 Records 逐条变为数据。
- IP: 针对 ip 做运营商信息字段扩展。
- replace: 替换原有的字符串内容。
- UserAgent: 浏览器中的 user agent 信息解析,可以解析出包括设备、操作系统、版本号在内的多种信息。
- k8stag: 从 kubernetes 存储的文件名称中获取 pod、containerID 之类的 tags 信息进行转换。
- label: 增加标签,添加一个带有固定值的字段到数据中。
关于数据转换方式的详细介绍,请阅读数据转换。
发送数据
logkit Pro 支持多种数据发送平台如七牛大数据平台、MongoDB、InfluxDB 等,根据需要在左侧列表选取。完成这一步就可以在数据平台进行后续数据计算、分析、查看。典型地,发送数据至七牛大数据平台后,数据可以在workflow进行数据计算和导出。
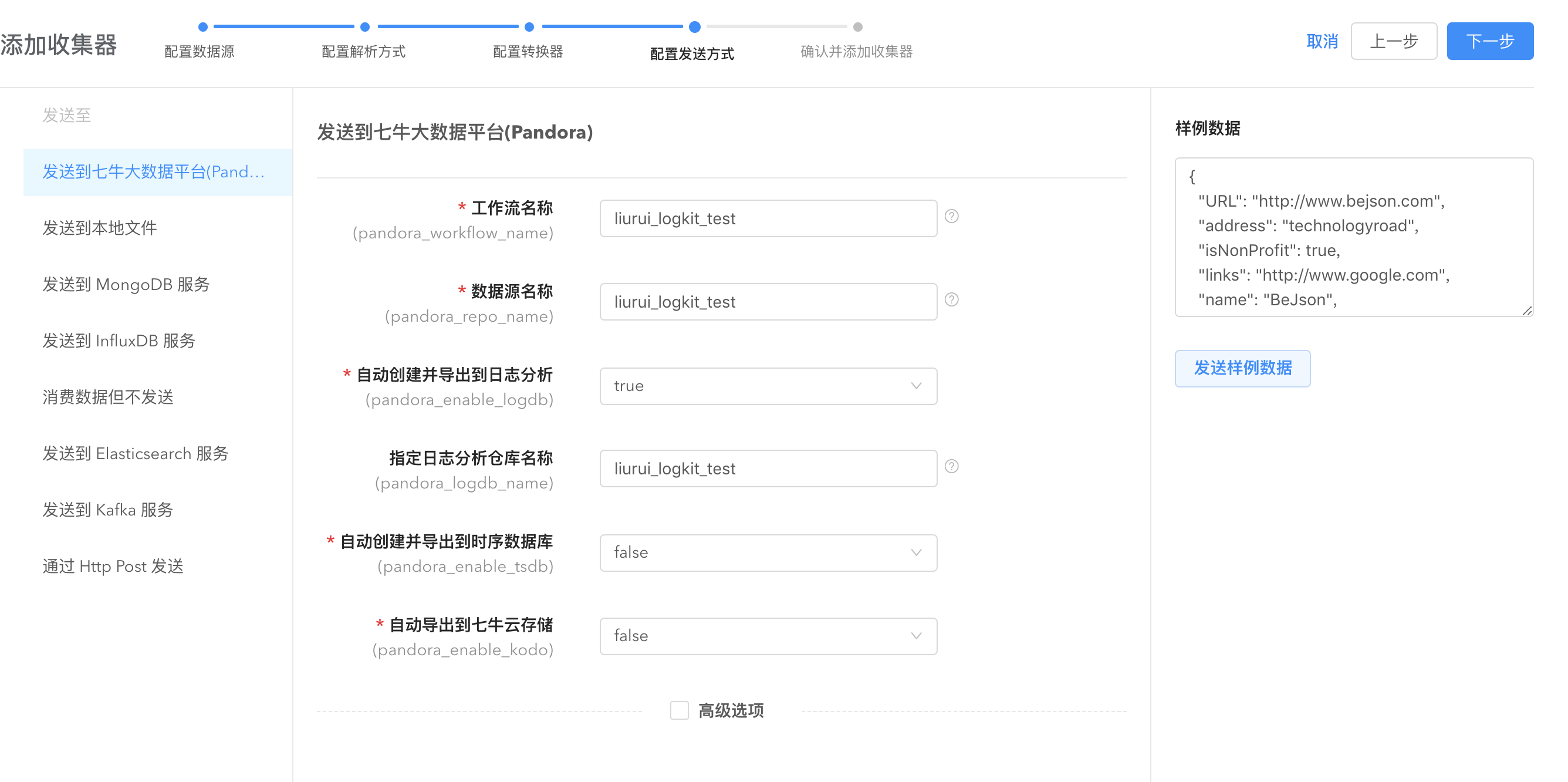
logkit Pro 支持的数据发送平台
- Pandora Sender: 发送到七牛大数据处理平台(Pandora)。
- File Sender: 发送到本地文件。
- MongoDB Accumulate Sender: 聚合后发送到 MongoDB 服务。
- InfluxDB Sender: 发送到 InfluxDB 服务。
- 消费数据但不发送:不执行发送行为。
- Elasticsearch Sender: 发送到 ElasticSearch 服务。
- Kafka Sender: 发送到 Kafka 服务。
- Http Sender: 以 Http POST 请求的方式发送数据。
关于数据发送平台配置的详细介绍,请阅读数据发送。
配置收集器操作案例可参考快速体验。
分发收集器
收集器配置好之后,将收集器分发到指定的机器实现收集器的统一管理。
点击【数据收集】->【收集器】进入收集器的分发和编辑。
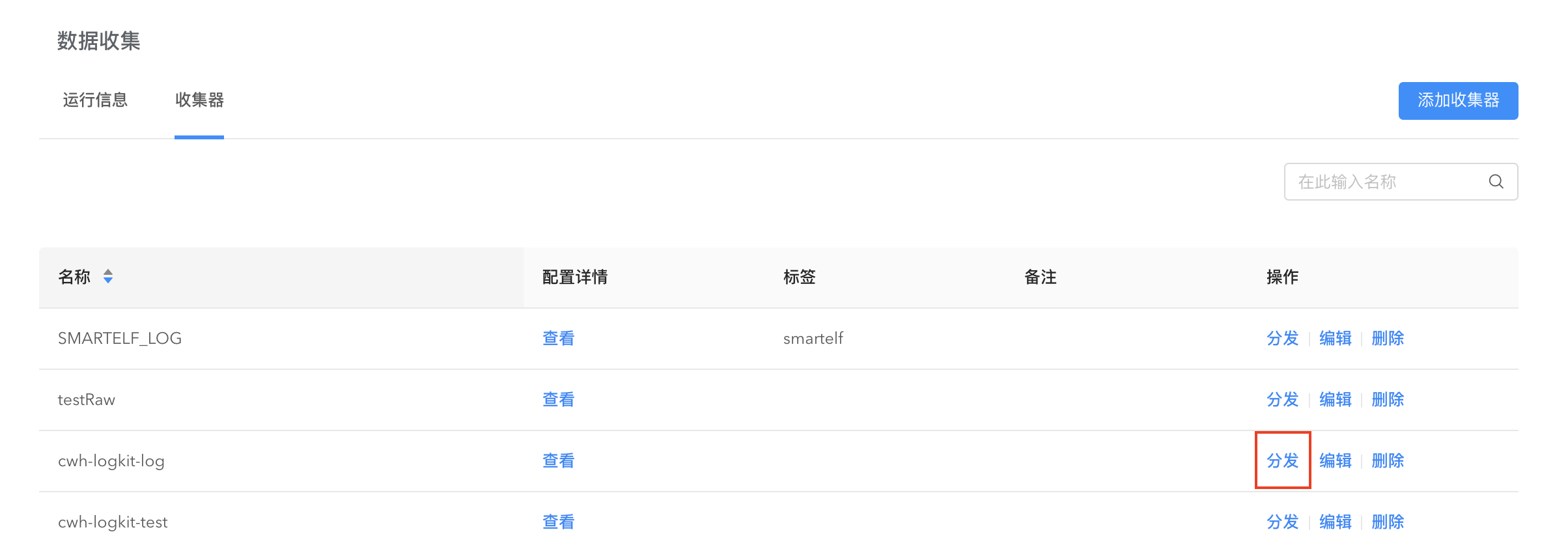
点击分发,可以将收集器分发到机器或者直接分发到标签。

点击编辑,可以更新收集器配置。
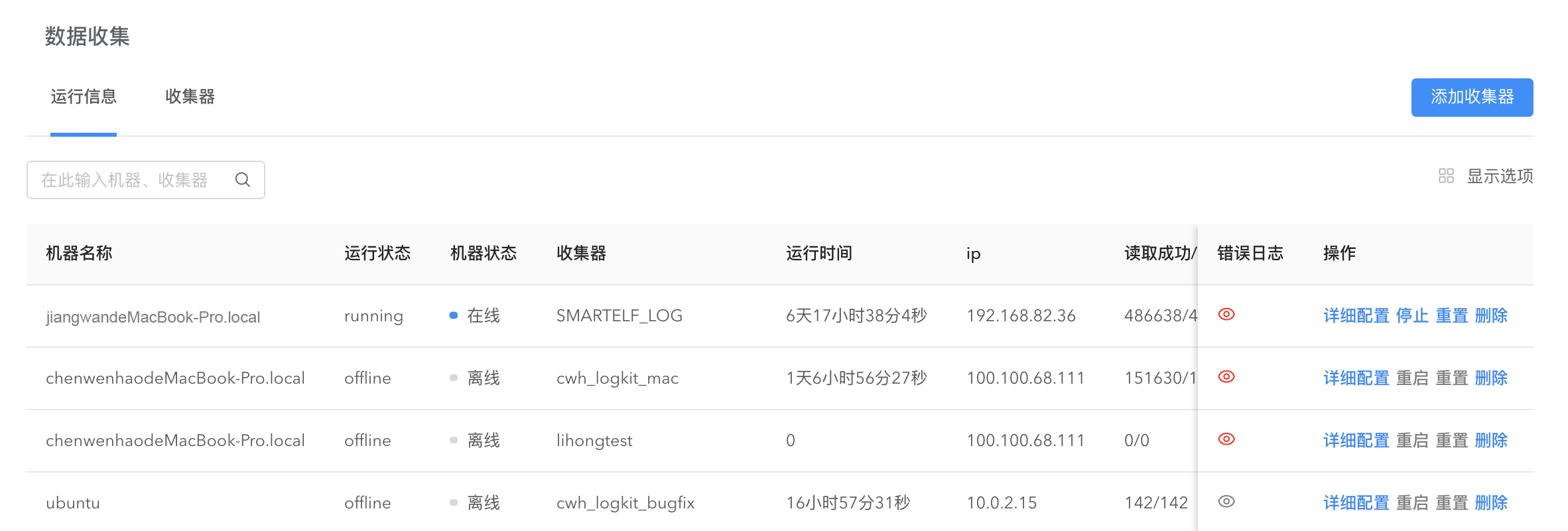
查看收集器运行信息
完成收集器的分发后,收集器就在机器成功运行。点击【数据收集】->【运行信息】即可查看收集器的运行信息,如运行时间、读取成功条数、解析成功条数、错误日志等,结合详细配置信息,及时查错。在这里您可以对每个收集器进行停止、重启、删除操作。
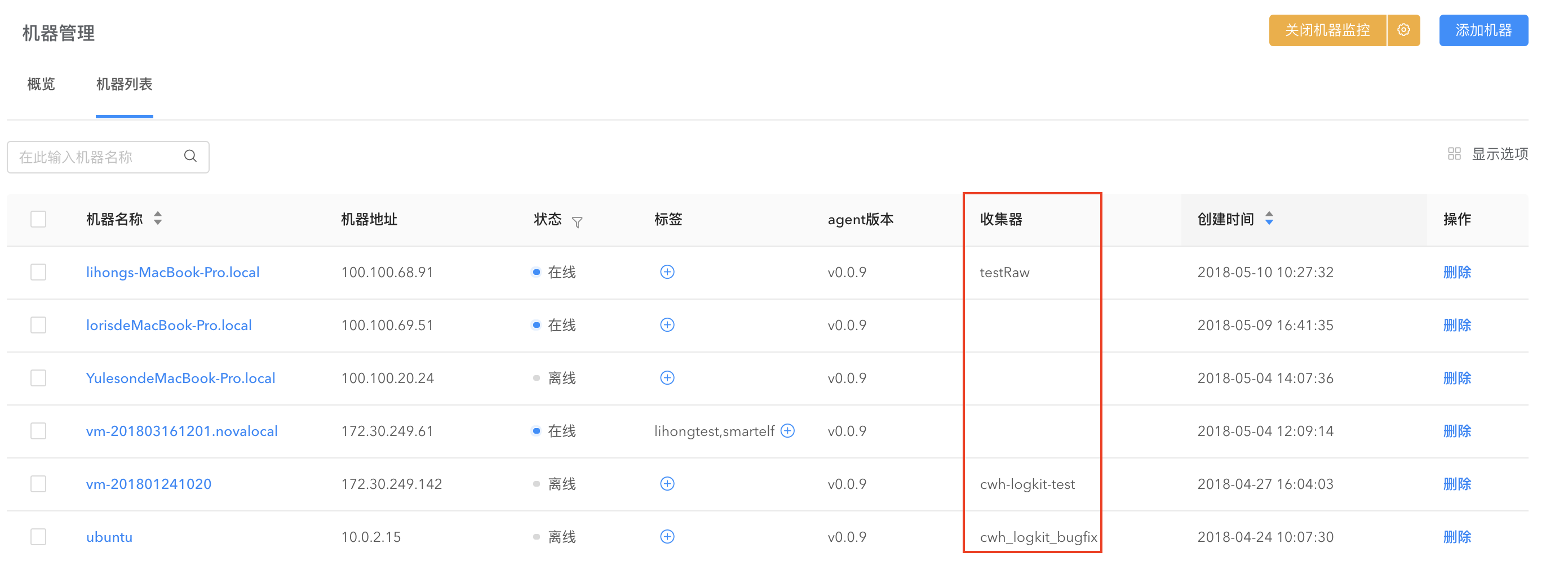
机器管理
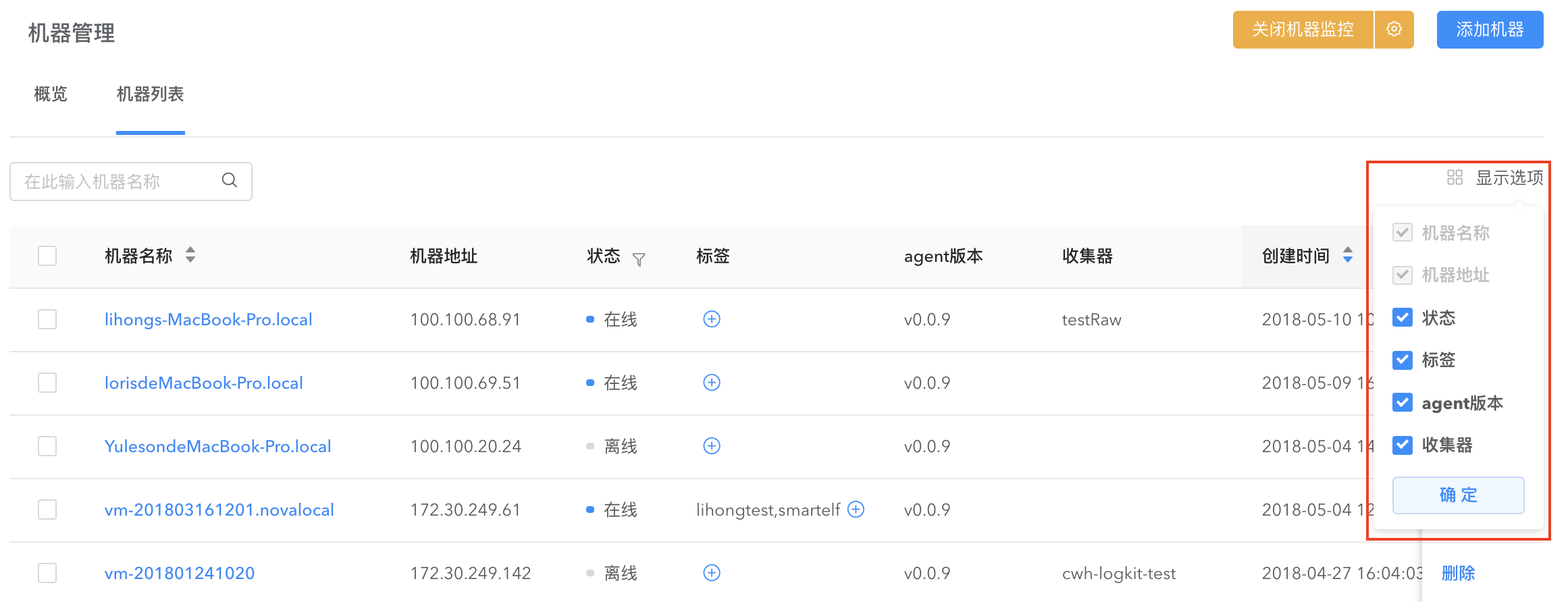
通过【机器管理】对机器运行状态进行监控。在【机器管理】界面可以看到已经添加进来的机器列表,显示机器地址、机器状态(在线、离线)等、该机器下的收集器等信息。
在右上角的显示选项勾选您感兴趣的显示信息。默认情况下,收集器信息不显示,需要手动勾选。
机器监控
logkit Pro 支持采集机器以及机器上部署的常见基础组件的各类指标数据对机器性能进行监控。
点击右上角【启动机器监控】,输入数据收集时间间隔与数据源名称收集机器性能信息并保存到 repo。之后您就可以在下游数据分析平台如 TSDB 查看机器性能数据。

启动机器监控以后,点击机器名称即可直接看到机器性能数据。

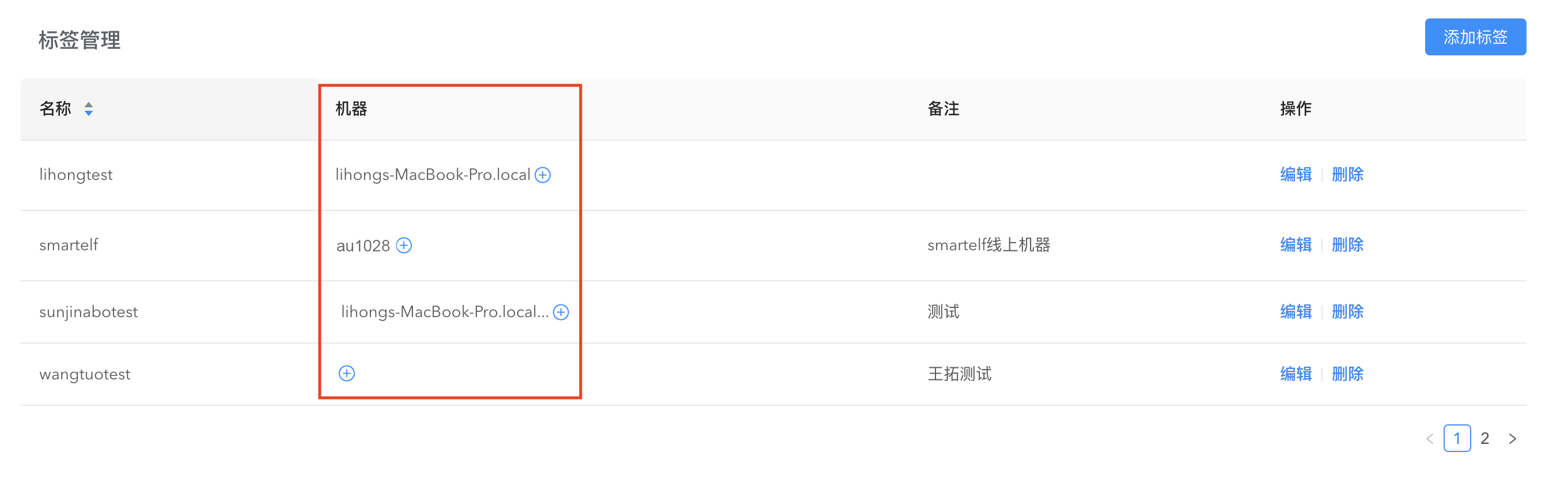
标签管理
通过标签管理功能来对同一个业务下的机器统一管理。在机器管理页面,点击添加标签按钮将指定机器添加到已有标签。


在弹出的添加标签窗口点击标签管理,可进入标签管理页面,对标签进行编辑、删除、创建标签操作。

您也可以在标签管理页面对指定标签添加机器来批量管理机器。
现在开始玩转您的 logkit Pro 吧!
