- 数据解析方式
- 按原始日志逐行发送(Raw Parser)
- 按 json 格式解析(JSON Parser)
- 按 nginx 日志解析(Nginx Parser)
- Nginx Parser 的解析原理
- grok格式解析
- 按 csv 格式解析(CSV Parser)
- 按 syslog 格式解析(Syslog Parser)
- 按七牛日志库格式解析(Qiniu Log Parser)
- 按 kafkarest 日志解析(KafkaRest Log Parser)
- 按 mysql 慢请求日志解析(mysql log parser)
数据解析方式
按原始日志逐行发送(Raw Parser)
Raw Parser 将日志文件的每一行解析为一条日志,解析后的日志有两个字段,raw 和 timestamp,前者是每一行日志的具体内容(若为空行,则忽略),后者为解析该条日志的时间戳。
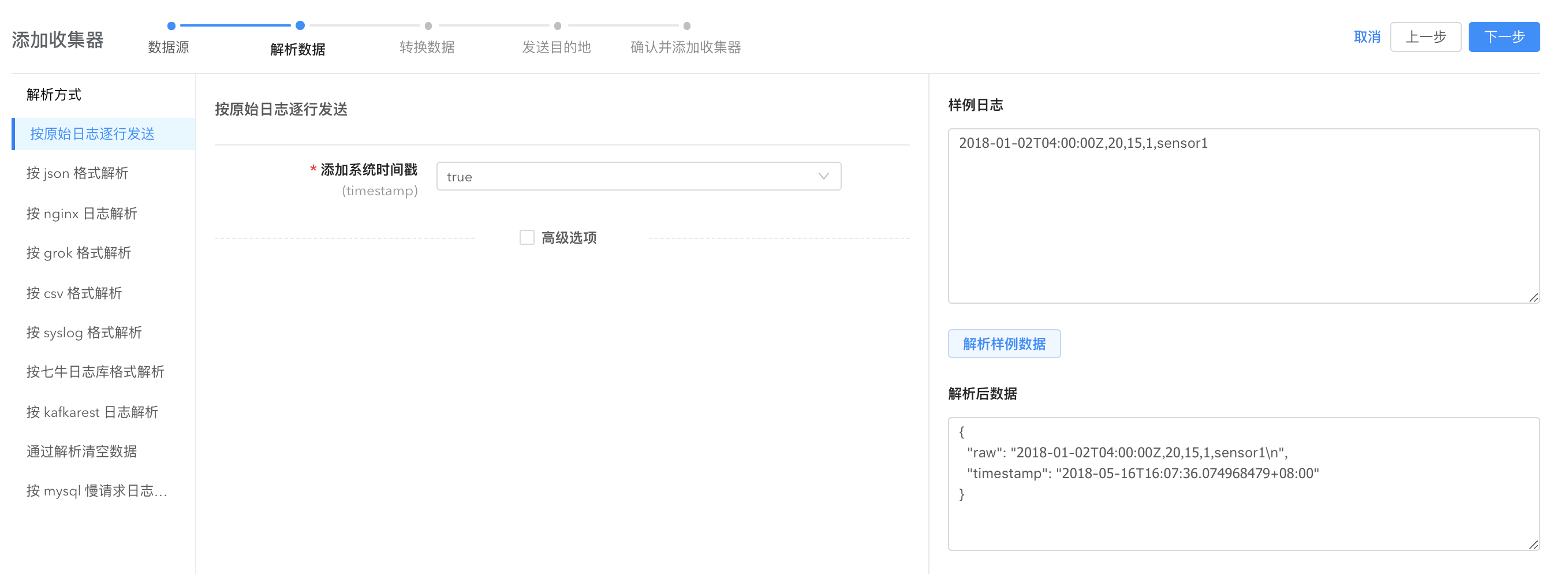
高级选项
额外的标签信息(labels): 填一些额外的标签信息,同样逗号分隔,每个部分由空格隔开,左边是标签的 key,右边是value。
按 json 格式解析(JSON Parser)
JSON parser 是一个 schema free 的 parser,会把 json 的字符串反序列化成 Golang 中map[string]interface{} 的形式,然后交由 sender 做处理。若日志的 json 格式不规范,则解析失败,解析失败的数据会被忽略。
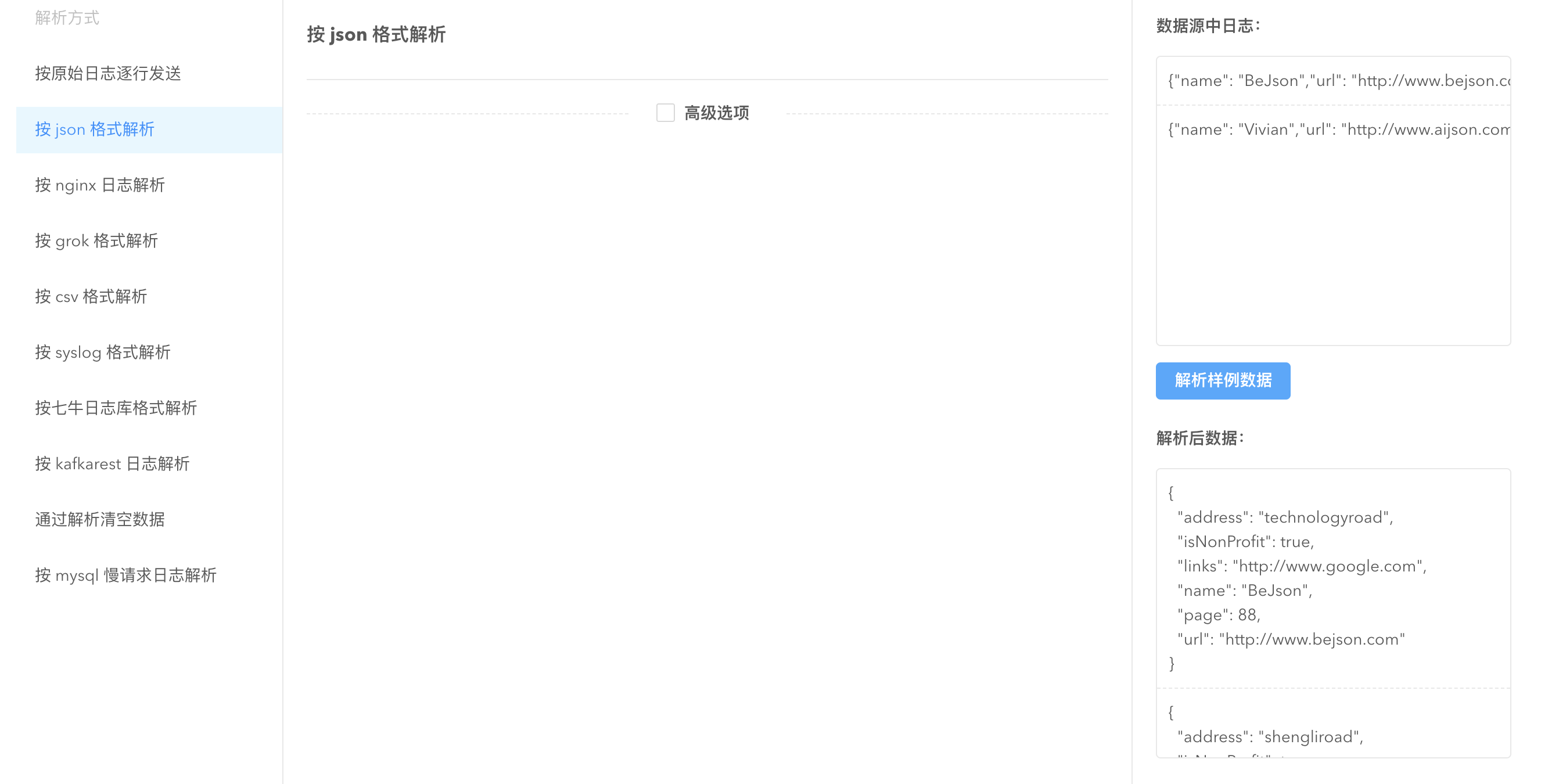
高级选项
额外的标签信息(labels):labels 中定义的标签如果跟数据有冲突,labels 中的标签会被舍弃
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在 “pandora_stash” 字段,该选项可以禁止记录解析失败的数据。
按 nginx 日志解析(Nginx Parser)
Nginx Parser 是专门解析 Nginx 日志的解析器。仅需指定 nginx 的配置文件地址,即可进行 nginx 日志解析。
Nginx Parser 的解析原理
Nginx Parser 会根据 Nginx 配置文件去寻找 Nginx 日志的生成格式,举例来说:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $bytes_sent $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for" ''$upstream_addr $host $sent_http_x_reqid $request_time';
这个日志格式会生成一个正则表达式,匹配每个$符号后的字符串,以格式中定义的分隔符为正则表达式的终结符。 如$remote_addr后面跟着空格,则认为匹配的 remote_addr 字段,匹配到空格为止。 如果被双引号””包裹,如"$http_user_agent",则认为匹配到双引号为止,又比如[$time_local]会认为匹配左括号[开始到右括号]结尾。
通过上述生成的正则表达式,就可以匹配 Nginx access日志了。
上述方式生成的正则表达式可以解析大部分情况下的 Nginx 配置,但是确实也存在一些情况会出现解析异常,如上述的 case 下,如果 http_user_agent 没有通过双引号引起来,那么就会导致提前匹配到 http_user_agent 中可能存在的空格,导致解析失败。针对这样的情况,我们就推荐使用Grok Parser来解析。
基础配置信息
nginx配置路径(nginx_log_format_path):填写 nginx 配置文件,配置文件中需要包含 log_format 格式。

nginx日志格式名称(nginx_log_format_name):实际 access log 使用的格式名称。

高级选项
手动指定字段类型(nginx_schema):默认情况下 nginx 日志都被解析为 string,指定该格式可以设置为float、long、date 等三种类型。指定范式为逗号分隔每个字段和类型,每个字段和类型用空格分隔,左边为字段名称,右边为类型。
指定名称(name):Nginx Parser 是根据您 Nginx 配置文件自动生成配置正则表达式解析日志的方式,parser名称和 Nginx 配置文件中 log_format 定义的名称一致。
额外的标签信息(labels):中定义的标签如果跟数据有冲突,labels 中的标签会被舍弃
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在”pandora_stash”字段,该选项可以禁止记录解析失败的数据。
grok格式解析
Grok Parser 是一个类似于 Logstash Grok Parser 一样的解析配置方式,其本质是按照正则表达式匹配解析日志。
基础配置信息
匹配日志的 grok 表达式(grok_patterns):用于匹配日志的 grok 表达式,多个用逗号分隔。填写解析日志的grok pattern 名称,包括一些logkit Pro 自身内置的 patterns以及自定义的 pattern 名称,以及社区的常见 grok pattern,如logstash 的内置 pattern以及常见的grok 库 pattern
- 填写方式是 %{QINIU_LOG_FORMAT},%{COMMON_LOG_FORMAT},以百分号和花括号包裹 pattern 名称,多个 pattern 名称以逗号分隔。
- 实际匹配过程中会按顺序依次去 parse 文本内容,以第一个匹配的 pattern 解析文本内容。
- 需要注意的是,每多一个 pattern,解析时都会多解析一个,直到成功为止,所以 pattern 的数量多有可能降低解析的速度,在数据量大的情况下,建议一个 pattern 解决数据解析问题。
自定义grok表达式(grok_custom_patterns):用户自定义的 grok pattern 内容,需符合 logkit Pro 自定义 pattern 的写法,按行分隔,参见自定义 pattern 的写法和用法说明。
Grok Parser 中解析出的字段就是 grok 表达式中命名的字段,还包括 labels 中定义的标签名,可以在 sender 中选择需要发送的字段和标签。
高级选项
自定义 grok 表达式文件路径(grok_custom_pattern_files):用户自定义的一些 grok pattern 文件,当自定义 pattern 太长太多,建议用文件功能。 !!!注意:如果修改 pattern 文件,需要更新 Runner 才能生效!!!
时区偏移量(timezone_offset): 解析出的时区信息默认为 UTC 时区,使用 timezone_offset 可以修改时区偏移量,默认偏移量为 0,写法为”+08”、”08”、”8” 均表示比读取时间加8小时,”-08”,”-8”,表示比读取的时间减 8 小时。若实际为东八区时间,读取为 UTC 时间,则实际多读取了 8 小时,需要写”-8”,修正回 CST 中国北京时间。
logkit Pro 自定义 pattern
- logkit Pro 的 grok pattern 其格式符合 %{<捕获语法>[:<字段名>][:<字段类型>]},其中中括号的内容可以省略。
- logkit Pro 的 grok pattern 是 logstash grok pattern 的增强版,除了完全兼容logstash grok pattern规则以外,还增加了类型,与telegraf 的 grok pattern规则一致,但是使用的类型是 logkit Pro 自身定义的。你可以在logstash grok文档中找到详细的 grok 介绍.
- 捕获语法:是一个正则表达式的名字,比如内置了 USERNAME [a-zA-Z0-9._-]+,那么此时 USERNAME 就是一个捕获语法。所以,在使用自定义的正则表达式之前,你需要先为你的正则命名,然后把这个名字当作捕获语法填写patterns 中,当然,不推荐自己写正则,建议首选内置的捕获语法。
- 字段名:按照捕获语法对应的正则表达式解析出的字段,其字段名称以此命名,该项可以不填,但是没有字段名的 grok pattern 不解析,无法被 logkit sender 使用,但可以作为一个中间捕获语法与别的捕获语法共同组合一个新的捕获语法。
- 字段类型:可以不填,默认为 string。logkit Pro 支持以下类型。
- string 默认的类型
- long 整型
- float 浮点型
- date 时间类型,包括以下格式 - 2006/01/02 15:04:05,
- 2006-01-02 15:04:05 -0700 MST,
- 2006-01-02 15:04:05 -0700,
- 2006-01-02 15:04:05,
- 2006/01/02 15:04:05 -0700 MST,
- 2006/01/02 15:04:05 -0700,
- 2006-01-02 -0700 MST,
- 2006-01-02 -0700,
- 2006-01-02,
- 2006/01/02 -0700 MST,
- 2006/01/02 -0700,
- 2006/01/02,
- Mon Jan _2 15:04:05 2006 ANSIC,
- Mon Jan _2 15:04:05 MST 2006 UnixDate,
- Mon Jan 02 15:04:05 -0700 2006 RubyDate,
- 02 Jan 06 15:04 MST RFC822,
- 02 Jan 06 15:04 -0700 RFC822Z,
- Monday, 02-Jan-06 15:04:05 MST RFC850,
- Mon, 02 Jan 2006 15:04:05 MST RFC1123,
- Mon, 02 Jan 2006 15:04:05 -0700 RFC1123Z,
- 2006-01-02T15:04:05Z07:00 RFC3339,
- 2006-01-02T15:04:05.999999999Z07:00 RFC3339Nano,
- 3:04PM Kitchen,
- Jan _2 15:04:05 Stamp,
- Jan _2 15:04:05.000 StampMilli,
- Jan _2 15:04:05.000000 StampMicro,
- Jan _2 15:04:05.000000000 StampNano,
- drop 表示扔掉该字段
- 验证自定义 pattern 的正确性:http://grokdebug.herokuapp.com, 这个网站可以 debug 你的 grok pattern。
如何调试您的 grok pettern[grokdebug用法]
- 访问地址:http://grokdebug.herokuapp.com
- 如下图所示,填写各类信息:
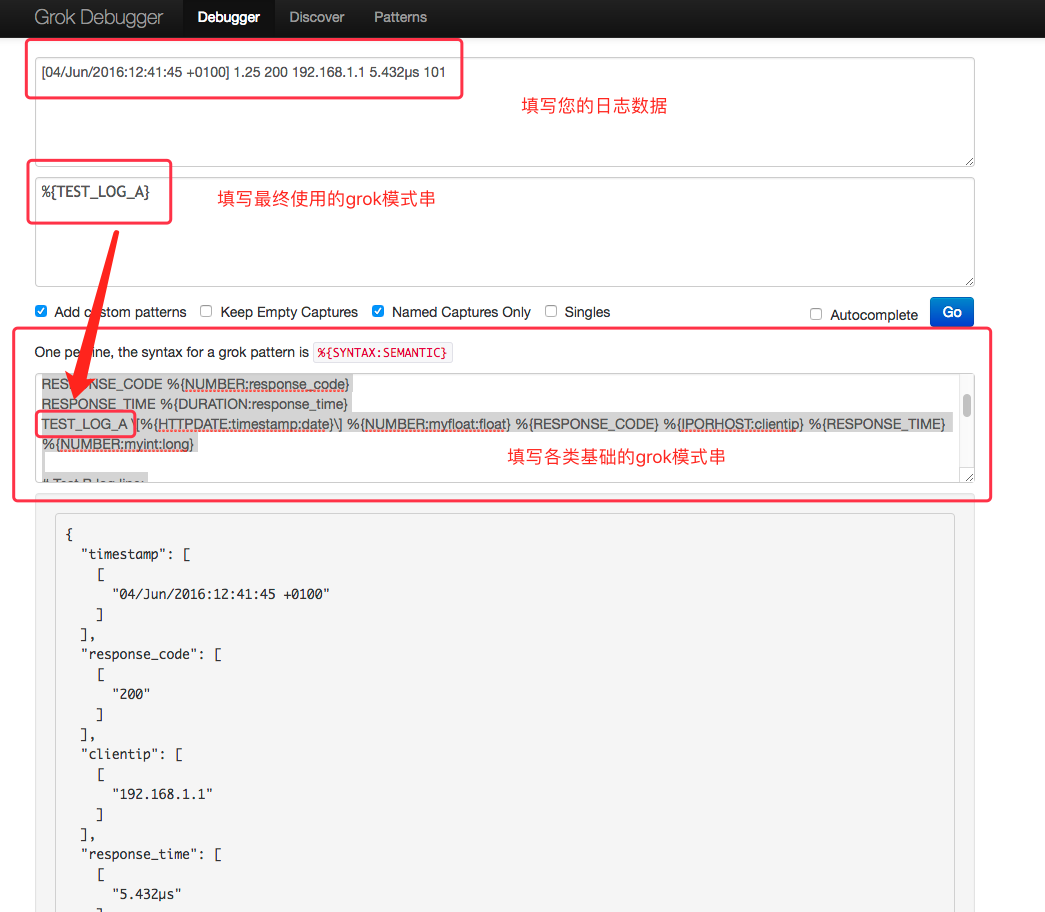
一条示例日志:
[04/Jun/2016:12:41:45 +0100] 1.25 200 192.168.1.1 5.432µs 101
最终使用的grok pattern
%{TEST_LOG_A}
基础的grok pattern 构成
# Test A log line:# [04/Jun/2016:12:41:45 +0100] 1.25 200 192.168.1.1 5.432µs 101DURATION %{NUMBER}[nuµm]?sRESPONSE_CODE %{NUMBER:response_code}RESPONSE_TIME %{DURATION:response_time}TEST_LOG_A \[%{HTTPDATE:timestamp:date}\] %{NUMBER:myfloat:float} %{RESPONSE_CODE} %{IPORHOST:clientip} %{RESPONSE_TIME} %{NUMBER:myint:long}# Test B log line:# [04/06/2016--12:41:45] 1.25 mystring dropme nomodifierTEST_TIMESTAMP %{MONTHDAY}/%{MONTHNUM}/%{YEAR}--%{TIME}TEST_LOG_B \[%{TEST_TIMESTAMP:timestamp:date}\] %{NUMBER:myfloat:float} %{WORD:mystring:string} %{WORD:dropme:drop} %{WORD:nomodifier}
将 grok pattern debug 调试完成后的配置落实到logkit Pro 的 grok 解析中,有以下两种方式:
- 将
基础的 grok pattern 构成里面的 grok pattern 填写到本地文件中,假设存储路径为 /home/user/logkit/grok_pattern。 注意,若修改这个 /home/user/logkit/grok_pattern 配置文件,需要更新 runner 才能生效。 - 将
最终使用的 grok pattern里面的模式串,填写到 grok parser 的 grok_patterns 配置项:”grok_patterns”:”%{TEST_LOG_A}”
如何使用 grok parser 解析 nginx/apache 日志
使用 grok parser 解析 nginx/apache 日志的过程,实际上就是利用 grok pattern(正则表达式)去匹配您的 nginx 日志,对于像 nginx/apache 日志这样的成熟日志内容,日志的所有组成部分均已经有非常成熟的 grok pattern 可以使用,下面我们先介绍下用于解析 nginx/apache 日志时常用的几个内置在 logkit Pro 的 grok pattern。
- 常用 grok pattern介绍
- NOTSPACE 匹配所有非空格的内容,这个是性能较高且最为常用的一个 pattern,比如你的日志内容是 abc efg,那么你只要写两个 NOTSPACE 的组合 Pattern 即可,如 %{NOTSPACE:field1} %{NOTSPACE:field2}。
- QUOTEDSTRING , 匹配所有被双引号括起来的字符串内容,跟 NOTSAPCE 类似,会包含双引号一起解析出来,如 “abc” - “efx sx” 这样一串日志,写一个组合 Pattern%{QUOTEDSTRING:field1} - %{QUOTEDSTRING:field2},field2 就包含数据”efx sx”,这个同样性能较高,好处是不怕有空格等其他特殊字符,缺点是解析的内容包含了双引号本身,如果要转换成 long 等类型需要去掉引号。
- DATA 匹配所有字符,这个 pattern 需要结合一些特殊的语境使用,如双引号等特殊字符。举例来说 “abc” - “efx sx”,这样一串日志,可以写一个组合 Pattern “%{DATA:field1}” - “%{DATA:field2}”,这个就起到了 QUOTEDSTRING 的效果,另外数据中不会包含双引号。
- HTTPDATE 匹配常见的 HTTP 日期类型,类似 nginx 和 Apache 生产的 timestamp 都可以用这个 Pattern 解析。如[30/Sep/2017:10:50:53 +0800],就可以写一个组合 Pattern [%{HTTPDATE:ts:date}],中括号里面包含 HTTPDATE 这个 Pattern,就把时间字符串匹配出来了。
- NUMBER 匹配数字类型,包括整数和浮点数,利用这个 Pattern 就可以把 nginx 里面的如响应时间这样的数据解析出来。如”10.10.111.117:8888” [200] “0.002”,就可以写 “%{NOTSPACE:ip}” [%{NUMBER:status:long}] “%{NUMBER:resptime:float}” 来解析出 status 状态码以及 resptime 响应时间。
基本上,上述这些基础的 grok Pattern 组合起来,就可以解决几乎所有 nginx 的日志解析,但有时候会遇到一些特殊情况,如某个字段可能存在也可能不存在,比如如下两行日志,我们都希望解析。
- POST 中包含HTTP协议信息
"POST /resouce/abc HTTP/1.1"
- POST 中不包含协议信息
"GET /resouce/abc"
此时就需要编写一种组合场景,表达或的逻辑,此时可以在 Pattern 组合中融入正则表达式的组概念,如下串即可解析:
"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion}))"
其中括号就是正则表达式的组,组里面还可以包含组,每个组通过”?”问号开头表示可以存在0次或1次,”:”冒号后表达匹配的内容。
在 nginx 日志中常常还会出现内容为空的情况,为空时 nginx 字段填充-横杠,此时也可以用类似的方法写或。 如这两种数据 0.123 以及 -,如果把”-“当成正常的数字去解析,就会出错,所以需要去掉没有数字的情况,如:
(?:%{NUMBER:bytes}|-)
最后,假设我们遇到一种不太规则的 nginx 日志写法,如:
110.220.330.550 - - [12/Oct/2017:14:16:50 +0800] "POST /v2/repos/xsxsxs/data HTTP/1.1" 200 729 2 "-" "Faraday v0.13.1" "-" 127.9.2.1:80 www.qiniu.com xsxsxsxsx122dxsxs 0.019
我们就可以用上面描述的方法拼接出如下的串:
NGINX_LOG %{NOTSPACE:client_ip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:ts:date}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version:float})?|%{DATA})" %{NUMBER:resp_code} (?:%{NUMBER:resp_bytes:long}|-) (?:%{NUMBER:resp_body_bytes:long}|-) "(?:%{NOTSPACE:referrer}|-)" %{QUOTEDSTRING:agent} %{QUOTEDSTRING:forward_for} %{NOTSPACE:upstream_addr} (%{HOSTNAME:host}|-) (%{NOTSPACE:reqid}) %{NUMBER:resp_time:float}
最后,你可以在 logkit Pro 的 grok parser 功能页面上调试一下。
按 csv 格式解析(CSV Parser)
CSV Parser 是一种按分隔符解析日志的解析方式,生成默认字段名与字段内容一一对应,字段名与字段类型可修改。
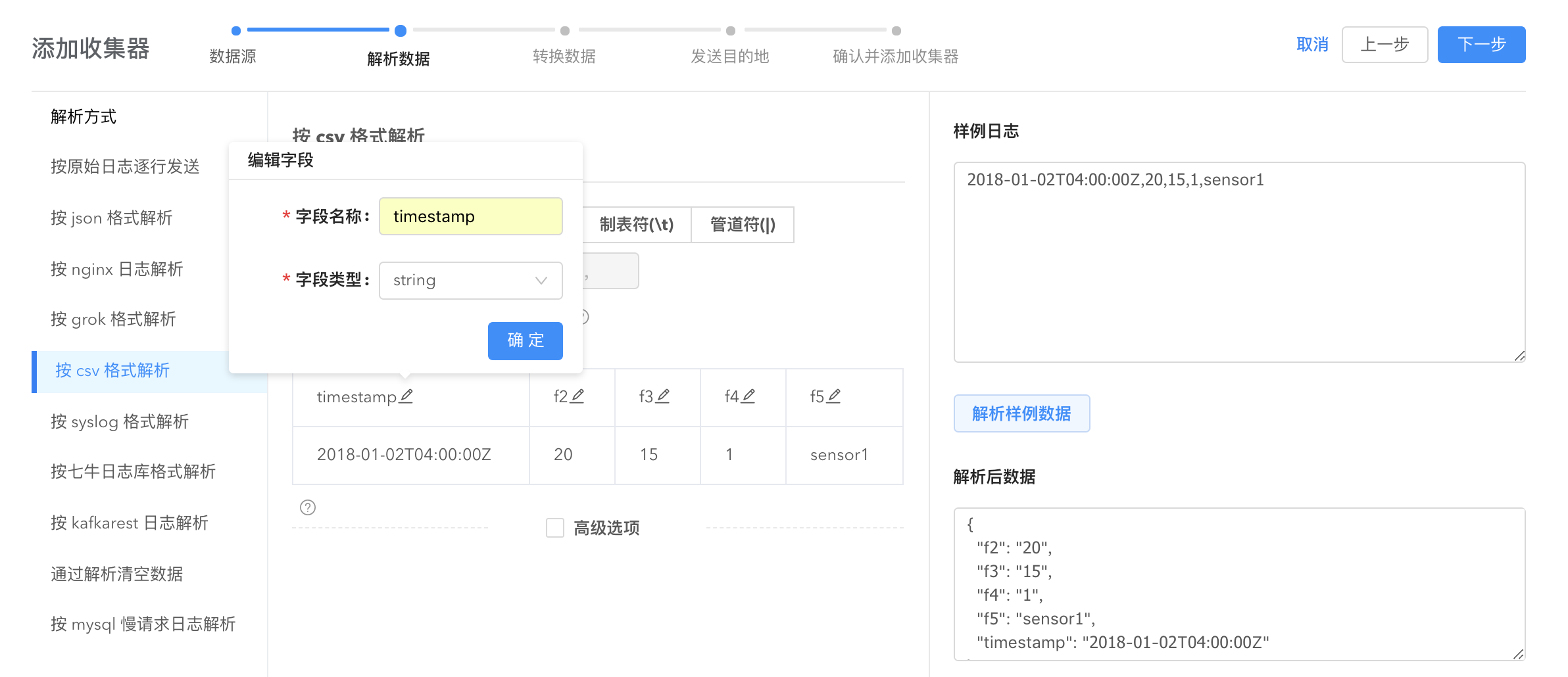
CSV parser 是按行读取日志的,对于每一行,以分隔符分隔,然后通过 csv_schema 命名分隔出来的字段名称以及字段类型。
默认情况下 CSV 是按 \t 分隔日志的,可以配置的分隔符包括但不限于, 各类字母、数字、特殊符号(#、!、*、@、%、^、…)等等。
- 分隔符(csv_splitter): csv文件的分隔符定义,默认为’\t’。
csv_schema 是按照逗号分隔的字符串,每个部分格式按照字段名、字段类型构成,字段类型现在支持 string, long, jsonmap, float,date。
- 类型说明
- string:go 的 string
- long:go 的 int 64
- float:go 的 float 64
- date:时间类型,具体参见grok date 字段解析类型
- jsonmap 将 json 反序列化为 map[string]interface{},key 必须为字符串格式,value 为 string, long 或者 float。如果 value 不属于这三种格式,将会强制将 value 转成 string 类型。
- jsonmap 如果要指定 jsonmap key 的类型并且选定一些 jsonmap 中的 key,那么只要用花括号包含选定的 key 以及其类型即可,里面的语法与外部相同也是以逗号”,”分隔不同的 key 和类型。目前不支持嵌套的 jsonmap,如果除了选定的 key,其他的 key也要,就以”…“结尾即可。
按 syslog 格式解析(Syslog Parser)
Syslog Parser 是直接根据 RFC3164/RFC5424 规则解析 syslog 数据的解析器,使用该解析器请确保日志数据严格按照 RFC 协议规则配置,否则该解析器将无法正确解析。
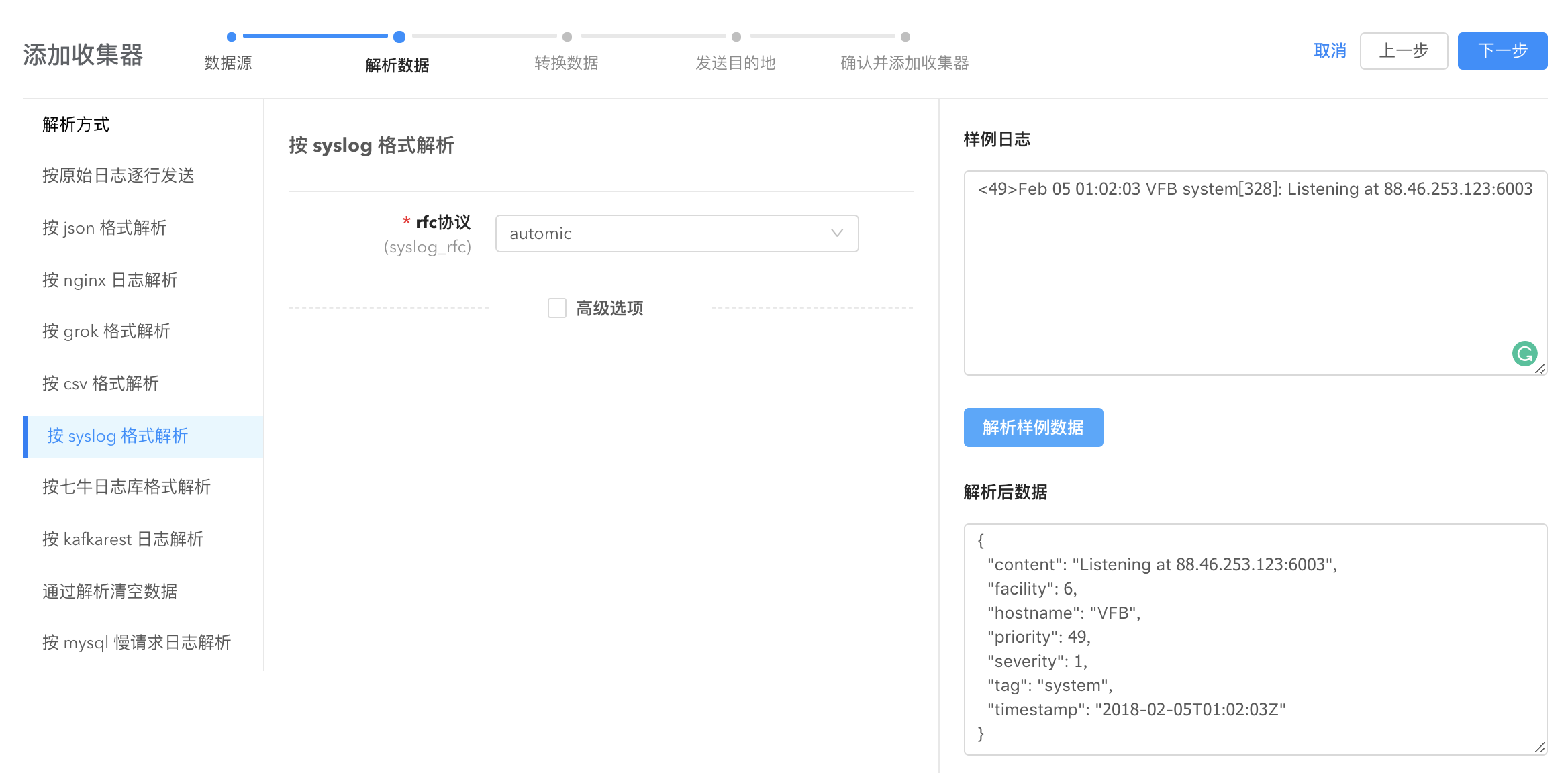
RFC 3164 : https://tools.ietf.org/html/rfc3164 样例日志如下:
<13>Feb 5 17:32:18 10.0.0.99 Use the BFG!
RFC 5424 : https://tools.ietf.org/html/rfc5424 样例日志如下:
<165>1 2003-10-11T22:14:15.003Z mymachine.example.com evntslog - ID47 [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"] BOMAn application event log entry...
Syslog Parser 能够自动识别多行构成的同一条日志。
rfc 协议(syslog_rfc):表示日志针对的 RFC 标准,选择 automic 可以识别,也可以直接填写 rfc3164 或者 rfc5424。
禁止记录解析失败数据(disable_record_errdata):默认为 false,解析失败的数据会默认出现在”pandora_stash”字段,该选项可以禁止记录解析失败的数据。
按七牛日志库格式解析(Qiniu Log Parser)
Qiniu Log Parser 为使用了七牛开源的 Golang 日志库https://github.com/qiniu/log 生成的日志提供的解析方式。
高级选项
日志前缀(qiniulog_prefix):使用 https://github.com/qiniu/log 这个库时用到的前缀,若没用上,就不填,通常情况下没有配置,默认不填。
日志格式顺序(qiniulog_log_headers):指定字段名称的顺序, 默认为 prefix、date、time、reqid、level、file
- prefix: qiniulog 的前缀,默认为空,不解析。
- date: 日志日期
- time: 日志时间
- reqid: 日志中用户请求的ID
- level: 日志等级
- file: 日志产生的代码位置
- 可以配置成: prefix,date,time,level,reqid,file,log
log 字段表示日志体的内容,顺序一定是在最后,不能改变。
最终 qiniu log parser 解析出来的字段为 prefix、date、time、reqid、level、file、log 以及标签,可以在 sender 中选择需要发送的字段和标签。
按 kafkarest 日志解析(KafkaRest Log Parser)
KafkaRest Log Parser 将 Kafka Rest 日志文件的每一行解析为一条结构化的日志。
- KafkaRestLog 解析出的字段名是固定的,包括如下字段及标签,可以在 sender 中选择需要发送的字段和标签。
- source_ip: 源 IP
- method: 请求的方法,诸如 POST、GET、PUT、DELETE 等
- topic: 请求涉及的 kafka topic
- code: httpcode
- resp_len: 请求长度
- duration: 请求时长
- log_time: 日志产生的时间
- error: 表示是一条 error 日志,也只有 error 日志才解析出该字段
- warn: 表示是一条 warn 日志,也只有 warn 日志才解析出该字段
按 mysql 慢请求日志解析(mysql log parser)
mysql log parser 解析的是 mysql 的慢请求日志。
针对如下一条慢请求日志:
# Time: 2017-12-24T02:42:00.126000Z# User@Host: rdsadmin[rdsadmin] @ localhost [127.0.0.1] Id: 3# Query_time: 0.020363 Lock_time: 0.018450 Rows_sent: 0 Rows_examined: 1SET timestamp=1514083320;use foo;SELECT count(*) from mysql.rds_replication_status WHERE master_host IS NOT NULL and master_port IS NOT NULL GROUP BY action_timestamp,called_by_user,action,mysql_version,master_host,master_port ORDER BY action_timestamp LIMIT 1;
可以解析得到的数据为:
{"SamplePoints": [{"Database": "foo","Host": "localhost","Lock_time": 0.01845,"Query_time": 0.020363,"Rows_examined": 1,"Rows_sent": 0,"Statement": "SELECT count(*) from mysql.rds_replication_status WHERE master_host IS NOT NULL and master_port IS NOT NULL GROUP BY action_timestamp,called_by_user,action,mysql_version,master_host,master_port ORDER BY action_timestamp LIMIT 1;","Timestamp": "2017-12-24T02:42:00Z","User": "rdsadmin"}]}
