- 1.6 常见的并发模式
- 1.6.1 并发版本的Hello world
- 1.6.2 生产者消费者模型
- 1.6.3 发布订阅模型
- 1.6.4 控制并发数
- 1.6.5 赢者为王
- 1.6.6 素数筛
- 1.6.7 并发的安全退出
- 1.6.8 context包
1.6 常见的并发模式
Go语言最吸引人的地方是它内建的并发支持。Go语言并发体系的理论是C.A.R Hoare在1978年提出的CSP(Communicating Sequential Process,通讯顺序进程)。CSP有着精确的数学模型,并实际应用在了Hoare参与设计的T9000通用计算机上。从NewSqueak、Alef、Limbo到现在的Go语言,对于对CSP有着20多年实战经验的Rob Pike来说,他更关注的是将CSP应用在通用编程语言上产生的潜力。作为Go并发编程核心的CSP理论的核心概念只有一个:同步通信。关于同步通信的话题我们在前面一节已经讲过,本节我们将简单介绍下Go语言中常见的并发模式。
首先要明确一个概念:并发不是并行。并发更关注的是程序的设计层面,并发的程序完全是可以顺序执行的,只有在真正的多核CPU上才可能真正地同时运行。并行更关注的是程序的运行层面,并行一般是简单的大量重复,例如GPU中对图像处理都会有大量的并行运算。为更好的编写并发程序,从设计之初Go语言就注重如何在编程语言层级上设计一个简洁安全高效的抽象模型,让程序员专注于分解问题和组合方案,而且不用被线程管理和信号互斥这些繁琐的操作分散精力。
在并发编程中,对共享资源的正确访问需要精确的控制,在目前的绝大多数语言中,都是通过加锁等线程同步方案来解决这一困难问题,而Go语言却另辟蹊径,它将共享的值通过Channel传递(实际上多个独立执行的线程很少主动共享资源)。在任意给定的时刻,最好只有一个Goroutine能够拥有该资源。数据竞争从设计层面上就被杜绝了。为了提倡这种思考方式,Go语言将其并发编程哲学化为一句口号:
Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存来通信,而应通过通信来共享内存。
这是更高层次的并发编程哲学(通过管道来传值是Go语言推荐的做法)。虽然像引用计数这类简单的并发问题通过原子操作或互斥锁就能很好地实现,但是通过Channel来控制访问能够让你写出更简洁正确的程序。
1.6.1 并发版本的Hello world
我们先以在一个新的Goroutine中输出“Hello world”,main等待后台线程输出工作完成之后退出,这样一个简单的并发程序作为热身。
并发编程的核心概念是同步通信,但是同步的方式却有多种。我们先以大家熟悉的互斥量sync.Mutex来实现同步通信。根据文档,我们不能直接对一个未加锁状态的sync.Mutex进行解锁,这会导致运行时异常。下面这种方式并不能保证正常工作:
func main() {var mu sync.Mutexgo func(){fmt.Println("你好, 世界")mu.Lock()}()mu.Unlock()}
因为mu.Lock()和mu.Unlock()并不在同一个Goroutine中,所以也就不满足顺序一致性内存模型。同时它们也没有其它的同步事件可以参考,这两个事件不可排序也就是可以并发的。因为可能是并发的事件,所以main函数中的mu.Unlock()很有可能先发生,而这个时刻mu互斥对象还处于未加锁的状态,从而会导致运行时异常。
下面是修复后的代码:
func main() {var mu sync.Mutexmu.Lock()go func(){fmt.Println("你好, 世界")mu.Unlock()}()mu.Lock()}
修复的方式是在main函数所在线程中执行两次mu.Lock(),当第二次加锁时会因为锁已经被占用(不是递归锁)而阻塞,main函数的阻塞状态驱动后台线程继续向前执行。当后台线程执行到mu.Unlock()时解锁,此时打印工作已经完成了,解锁会导致main函数中的第二个mu.Lock()阻塞状态取消,此时后台线程和主线程再没有其它的同步事件参考,它们退出的事件将是并发的:在main函数退出导致程序退出时,后台线程可能已经退出了,也可能没有退出。虽然无法确定两个线程退出的时间,但是打印工作是可以正确完成的。
使用sync.Mutex互斥锁同步是比较低级的做法。我们现在改用无缓存的管道来实现同步:
func main() {done := make(chan int)go func(){fmt.Println("你好, 世界")<-done}()done <- 1}
根据Go语言内存模型规范,对于从无缓冲Channel进行的接收,发生在对该Channel进行的发送完成之前。因此,后台线程<-done接收操作完成之后,main线程的done <- 1发送操作才可能完成(从而退出main、退出程序),而此时打印工作已经完成了。
上面的代码虽然可以正确同步,但是对管道的缓存大小太敏感:如果管道有缓存的话,就无法保证main退出之前后台线程能正常打印了。更好的做法是将管道的发送和接收方向调换一下,这样可以避免同步事件受管道缓存大小的影响:
func main() {done := make(chan int, 1) // 带缓存的管道go func(){fmt.Println("你好, 世界")done <- 1}()<-done}
对于带缓冲的Channel,对于Channel的第K个接收完成操作发生在第K+C个发送操作完成之前,其中C是Channel的缓存大小。虽然管道是带缓存的,main线程接收完成是在后台线程发送开始但还未完成的时刻,此时打印工作也是已经完成的。
基于带缓存的管道,我们可以很容易将打印线程扩展到N个。下面的例子是开启10个后台线程分别打印:
func main() {done := make(chan int, 10) // 带 10 个缓存// 开N个后台打印线程for i := 0; i < cap(done); i++ {go func(){fmt.Println("你好, 世界")done <- 1}()}// 等待N个后台线程完成for i := 0; i < cap(done); i++ {<-done}}
对于这种要等待N个线程完成后再进行下一步的同步操作有一个简单的做法,就是使用sync.WaitGroup来等待一组事件:
func main() {var wg sync.WaitGroup// 开N个后台打印线程for i := 0; i < 10; i++ {wg.Add(1)go func() {fmt.Println("你好, 世界")wg.Done()}()}// 等待N个后台线程完成wg.Wait()}
其中wg.Add(1)用于增加等待事件的个数,必须确保在后台线程启动之前执行(如果放到后台线程之中执行则不能保证被正常执行到)。当后台线程完成打印工作之后,调用wg.Done()表示完成一个事件。main函数的wg.Wait()是等待全部的事件完成。
1.6.2 生产者消费者模型
并发编程中最常见的例子就是生产者消费者模式,该模式主要通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。简单地说,就是生产者生产一些数据,然后放到成果队列中,同时消费者从成果队列中来取这些数据。这样就让生产消费变成了异步的两个过程。当成果队列中没有数据时,消费者就进入饥饿的等待中;而当成果队列中数据已满时,生产者则面临因产品挤压导致CPU被剥夺的下岗问题。
Go语言实现生产者消费者并发很简单:
// 生产者: 生成 factor 整数倍的序列func Producer(factor int, out chan<- int) {for i := 0; ; i++ {out <- i*factor}}// 消费者func Consumer(in <-chan int) {for v := range in {fmt.Println(v)}}func main() {ch := make(chan int, 64) // 成果队列go Producer(3, ch) // 生成 3 的倍数的序列go Producer(5, ch) // 生成 5 的倍数的序列go Consumer(ch) // 消费 生成的队列// 运行一定时间后退出time.Sleep(5 * time.Second)}
我们开启了2个Producer生产流水线,分别用于生成3和5的倍数的序列。然后开启1个Consumer消费者线程,打印获取的结果。我们通过在main函数休眠一定的时间来让生产者和消费者工作一定时间。正如前面一节说的,这种靠休眠方式是无法保证稳定的输出结果的。
我们可以让main函数保存阻塞状态不退出,只有当用户输入Ctrl-C时才真正退出程序:
func main() {ch := make(chan int, 64) // 成果队列go Producer(3, ch) // 生成 3 的倍数的序列go Producer(5, ch) // 生成 5 的倍数的序列go Consumer(ch) // 消费 生成的队列// Ctrl+C 退出sig := make(chan os.Signal, 1)signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)fmt.Printf("quit (%v)\n", <-sig)}
我们这个例子中有2个生产者,并且2个生产者之间并无同步事件可参考,它们是并发的。因此,消费者输出的结果序列的顺序是不确定的,这并没有问题,生产者和消费者依然可以相互配合工作。
1.6.3 发布订阅模型
发布订阅(publish-and-subscribe)模型通常被简写为pub/sub模型。在这个模型中,消息生产者成为发布者(publisher),而消息消费者则成为订阅者(subscriber),生产者和消费者是M:N的关系。在传统生产者和消费者模型中,是将消息发送到一个队列中,而发布订阅模型则是将消息发布给一个主题。
为此,我们构建了一个名为pubsub的发布订阅模型支持包:
// Package pubsub implements a simple multi-topic pub-sub library.package pubsubimport ("sync""time")type (subscriber chan interface{} // 订阅者为一个管道topicFunc func(v interface{}) bool // 主题为一个过滤器)// 发布者对象type Publisher struct {m sync.RWMutex // 读写锁buffer int // 订阅队列的缓存大小timeout time.Duration // 发布超时时间subscribers map[subscriber]topicFunc // 订阅者信息}// 构建一个发布者对象, 可以设置发布超时时间和缓存队列的长度func NewPublisher(publishTimeout time.Duration, buffer int) *Publisher {return &Publisher{buffer: buffer,timeout: publishTimeout,subscribers: make(map[subscriber]topicFunc),}}// 添加一个新的订阅者,订阅全部主题func (p *Publisher) Subscribe() chan interface{} {return p.SubscribeTopic(nil)}// 添加一个新的订阅者,订阅过滤器筛选后的主题func (p *Publisher) SubscribeTopic(topic topicFunc) chan interface{} {ch := make(chan interface{}, p.buffer)p.m.Lock()p.subscribers[ch] = topicp.m.Unlock()return ch}// 退出订阅func (p *Publisher) Evict(sub chan interface{}) {p.m.Lock()defer p.m.Unlock()delete(p.subscribers, sub)close(sub)}// 发布一个主题func (p *Publisher) Publish(v interface{}) {p.m.RLock()defer p.m.RUnlock()var wg sync.WaitGroupfor sub, topic := range p.subscribers {wg.Add(1)go p.sendTopic(sub, topic, v, &wg)}wg.Wait()}// 关闭发布者对象,同时关闭所有的订阅者管道。func (p *Publisher) Close() {p.m.Lock()defer p.m.Unlock()for sub := range p.subscribers {delete(p.subscribers, sub)close(sub)}}// 发送主题,可以容忍一定的超时func (p *Publisher) sendTopic(sub subscriber, topic topicFunc, v interface{}, wg *sync.WaitGroup,) {defer wg.Done()if topic != nil && !topic(v) {return}select {case sub <- v:case <-time.After(p.timeout):}}
下面的例子中,有两个订阅者分别订阅了全部主题和含有”golang”的主题:
import "path/to/pubsub"func main() {p := pubsub.NewPublisher(100*time.Millisecond, 10)defer p.Close()all := p.Subscribe()golang := p.SubscribeTopic(func(v interface{}) bool {if s, ok := v.(string); ok {return strings.Contains(s, "golang")}return false})p.Publish("hello, world!")p.Publish("hello, golang!")go func() {for msg := range all {fmt.Println("all:", msg)}} ()go func() {for msg := range golang {fmt.Println("golang:", msg)}} ()// 运行一定时间后退出time.Sleep(3 * time.Second)}
在发布订阅模型中,每条消息都会传送给多个订阅者。发布者通常不会知道、也不关心哪一个订阅者正在接收主题消息。订阅者和发布者可以在运行时动态添加,是一种松散的耦合关系,这使得系统的复杂性可以随时间的推移而增长。在现实生活中,像天气预报之类的应用就可以应用这个并发模式。
1.6.4 控制并发数
很多用户在适应了Go语言强大的并发特性之后,都倾向于编写最大并发的程序,因为这样似乎可以提供最大的性能。在现实中我们行色匆匆,但有时却需要我们放慢脚步享受生活,并发的程序也是一样:有时候我们需要适当地控制并发的程度,因为这样不仅仅可给其它的应用/任务让出/预留一定的CPU资源,也可以适当降低功耗缓解电池的压力。
在Go语言自带的godoc程序实现中有一个vfs的包对应虚拟的文件系统,在vfs包下面有一个gatefs的子包,gatefs子包的目的就是为了控制访问该虚拟文件系统的最大并发数。gatefs包的应用很简单:
import ("golang.org/x/tools/godoc/vfs""golang.org/x/tools/godoc/vfs/gatefs")func main() {fs := gatefs.New(vfs.OS("/path"), make(chan bool, 8))// ...}
其中vfs.OS("/path")基于本地文件系统构造一个虚拟的文件系统,然后gatefs.New基于现有的虚拟文件系统构造一个并发受控的虚拟文件系统。并发数控制的原理在前面一节已经讲过,就是通过带缓存管道的发送和接收规则来实现最大并发阻塞:
var limit = make(chan int, 3)func main() {for _, w := range work {go func() {limit <- 1w()<-limit}()}select{}}
不过gatefs对此做一个抽象类型gate,增加了enter和leave方法分别对应并发代码的进入和离开。当超出并发数目限制的时候,enter方法会阻塞直到并发数降下来为止。
type gate chan boolfunc (g gate) enter() { g <- true }func (g gate) leave() { <-g }
gatefs包装的新的虚拟文件系统就是将需要控制并发的方法增加了enter和leave调用而已:
type gatefs struct {fs vfs.FileSystemgate}func (fs gatefs) Lstat(p string) (os.FileInfo, error) {fs.enter()defer fs.leave()return fs.fs.Lstat(p)}
我们不仅可以控制最大的并发数目,而且可以通过带缓存Channel的使用量和最大容量比例来判断程序运行的并发率。当管道为空的时候可以认为是空闲状态,当管道满了时任务是繁忙状态,这对于后台一些低级任务的运行是有参考价值的。
1.6.5 赢者为王
采用并发编程的动机有很多:并发编程可以简化问题,比如一类问题对应一个处理线程会更简单;并发编程还可以提升性能,在一个多核CPU上开2个线程一般会比开1个线程快一些。其实对于提升性能而言,程序并不是简单地运行速度快就表示用户体验好的;很多时候程序能快速响应用户请求才是最重要的,当没有用户请求需要处理的时候才合适处理一些低优先级的后台任务。
假设我们想快速地搜索“golang”相关的主题,我们可能会同时打开Bing、Google或百度等多个检索引擎。当某个搜索最先返回结果后,就可以关闭其它搜索页面了。因为受网络环境和搜索引擎算法的影响,某些搜索引擎可能很快返回搜索结果,某些搜索引擎也可能等到他们公司倒闭也没有完成搜索。我们可以采用类似的策略来编写这个程序:
func main() {ch := make(chan string, 32)go func() {ch <- searchByBing("golang")}()go func() {ch <- searchByGoogle("golang")}()go func() {ch <- searchByBaidu("golang")}()fmt.Println(<-ch)}
首先,我们创建了一个带缓存的管道,管道的缓存数目要足够大,保证不会因为缓存的容量引起不必要的阻塞。然后我们开启了多个后台线程,分别向不同的搜索引擎提交搜索请求。当任意一个搜索引擎最先有结果之后,都会马上将结果发到管道中(因为管道带了足够的缓存,这个过程不会阻塞)。但是最终我们只从管道取第一个结果,也就是最先返回的结果。
通过适当开启一些冗余的线程,尝试用不同途径去解决同样的问题,最终以赢者为王的方式提升了程序的相应性能。
1.6.6 素数筛
在“Hello world 的革命”一节中,我们为了演示Newsqueak的并发特性,文中给出了并发版本素数筛的实现。并发版本的素数筛是一个经典的并发例子,通过它我们可以更深刻地理解Go语言的并发特性。“素数筛”的原理如图:
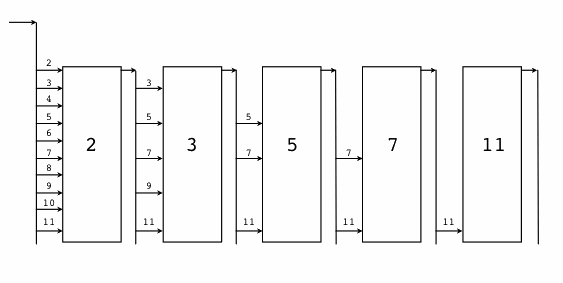
图 1-13 素数筛
我们需要先生成最初的2, 3, 4, ...自然数序列(不包含开头的0、1):
// 返回生成自然数序列的管道: 2, 3, 4, ...func GenerateNatural() chan int {ch := make(chan int)go func() {for i := 2; ; i++ {ch <- i}}()return ch}
GenerateNatural函数内部启动一个Goroutine生产序列,返回对应的管道。
然后是为每个素数构造一个筛子:将输入序列中是素数倍数的数提出,并返回新的序列,是一个新的管道。
// 管道过滤器: 删除能被素数整除的数func PrimeFilter(in <-chan int, prime int) chan int {out := make(chan int)go func() {for {if i := <-in; i%prime != 0 {out <- i}}}()return out}
PrimeFilter函数也是内部启动一个Goroutine生产序列,返回过滤后序列对应的管道。
现在我们可以在main函数中驱动这个并发的素数筛了:
func main() {ch := GenerateNatural() // 自然数序列: 2, 3, 4, ...for i := 0; i < 100; i++ {prime := <-ch // 新出现的素数fmt.Printf("%v: %v\n", i+1, prime)ch = PrimeFilter(ch, prime) // 基于新素数构造的过滤器}}
我们先是调用GenerateNatural()生成最原始的从2开始的自然数序列。然后开始一个100次迭代的循环,希望生成100个素数。在每次循环迭代开始的时候,管道中的第一个数必定是素数,我们先读取并打印这个素数。然后基于管道中剩余的数列,并以当前取出的素数为筛子过滤后面的素数。不同的素数筛子对应的管道是串联在一起的。
素数筛展示了一种优雅的并发程序结构。但是因为每个并发体处理的任务粒度太细微,程序整体的性能并不理想。对于细粒度的并发程序,CSP模型中固有的消息传递的代价太高了(多线程并发模型同样要面临线程启动的代价)。
1.6.7 并发的安全退出
有时候我们需要通知goroutine停止它正在干的事情,特别是当它工作在错误的方向上的时候。Go语言并没有提供在一个直接终止Goroutine的方法,由于这样会导致goroutine之间的共享变量处在未定义的状态上。但是如果我们想要退出两个或者任意多个Goroutine怎么办呢?
Go语言中不同Goroutine之间主要依靠管道进行通信和同步。要同时处理多个管道的发送或接收操作,我们需要使用select关键字(这个关键字和网络编程中的select函数的行为类似)。当select有多个分支时,会随机选择一个可用的管道分支,如果没有可用的管道分支则选择default分支,否则会一直保存阻塞状态。
基于select实现的管道的超时判断:
select {case v := <-in:fmt.Println(v)case <-time.After(time.Second):return // 超时}
通过select的default分支实现非阻塞的管道发送或接收操作:
select {case v := <-in:fmt.Println(v)default:// 没有数据}
通过select来阻止main函数退出:
func main() {// do some thinsselect{}}
当有多个管道均可操作时,select会随机选择一个管道。基于该特性我们可以用select实现一个生成随机数序列的程序:
func main() {ch := make(chan int)go func() {for {select {case ch <- 0:case ch <- 1:}}}()for v := range ch {fmt.Println(v)}}
我们通过select和default分支可以很容易实现一个Goroutine的退出控制:
func worker(cannel chan bool) {for {select {default:fmt.Println("hello")// 正常工作case <-cannel:// 退出}}}func main() {cannel := make(chan bool)go worker(cannel)time.Sleep(time.Second)cannel <- true}
但是管道的发送操作和接收操作是一一对应的,如果要停止多个Goroutine那么可能需要创建同样数量的管道,这个代价太大了。其实我们可以通过close关闭一个管道来实现广播的效果,所有从关闭管道接收的操作均会收到一个零值和一个可选的失败标志。
func worker(cannel chan bool) {for {select {default:fmt.Println("hello")// 正常工作case <-cannel:// 退出}}}func main() {cancel := make(chan bool)for i := 0; i < 10; i++ {go worker(cancel)}time.Sleep(time.Second)close(cancel)}
我们通过close来关闭cancel管道向多个Goroutine广播退出的指令。不过这个程序依然不够稳健:当每个Goroutine收到退出指令退出时一般会进行一定的清理工作,但是退出的清理工作并不能保证被完成,因为main线程并没有等待各个工作Goroutine退出工作完成的机制。我们可以结合sync.WaitGroup来改进:
func worker(wg *sync.WaitGroup, cannel chan bool) {defer wg.Done()for {select {default:fmt.Println("hello")case <-cannel:return}}}func main() {cancel := make(chan bool)var wg sync.WaitGroupfor i := 0; i < 10; i++ {wg.Add(1)go worker(&wg, cancel)}time.Sleep(time.Second)close(cancel)wg.Wait()}
现在每个工作者并发体的创建、运行、暂停和退出都是在main函数的安全控制之下了。
1.6.8 context包
在Go1.7发布时,标准库增加了一个context包,用来简化对于处理单个请求的多个Goroutine之间与请求域的数据、超时和退出等操作,官方有博文对此做了专门介绍。我们可以用context包来重新实现前面的线程安全退出或超时的控制:
func worker(ctx context.Context, wg *sync.WaitGroup) error {defer wg.Done()for {select {default:fmt.Println("hello")case <-ctx.Done():return ctx.Err()}}}func main() {ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)var wg sync.WaitGroupfor i := 0; i < 10; i++ {wg.Add(1)go worker(ctx, &wg)}time.Sleep(time.Second)cancel()wg.Wait()}
当并发体超时或main主动停止工作者Goroutine时,每个工作者都可以安全退出。
Go语言是带内存自动回收特性的,因此内存一般不会泄漏。在前面素数筛的例子中,GenerateNatural和PrimeFilter函数内部都启动了新的Goroutine,当main函数不再使用管道时后台Goroutine有泄漏的风险。我们可以通过context包来避免这个问题,下面是改进的素数筛实现:
// 返回生成自然数序列的管道: 2, 3, 4, ...func GenerateNatural(ctx context.Context) chan int {ch := make(chan int)go func() {for i := 2; ; i++ {select {case <- ctx.Done():returncase ch <- i:}}}()return ch}// 管道过滤器: 删除能被素数整除的数func PrimeFilter(ctx context.Context, in <-chan int, prime int) chan int {out := make(chan int)go func() {for {if i := <-in; i%prime != 0 {select {case <- ctx.Done():returncase out <- i:}}}}()return out}func main() {// 通过 Context 控制后台Goroutine状态ctx, cancel := context.WithCancel(context.Background())ch := GenerateNatural(ctx) // 自然数序列: 2, 3, 4, ...for i := 0; i < 100; i++ {prime := <-ch // 新出现的素数fmt.Printf("%v: %v\n", i+1, prime)ch = PrimeFilter(ctx, ch, prime) // 基于新素数构造的过滤器}cancel()}
当main函数完成工作前,通过调用cancel()来通知后台Goroutine退出,这样就避免了Goroutine的泄漏。
并发是一个非常大的主题,我们这里只是展示几个非常基础的并发编程的例子。官方文档也有很多关于并发编程的讨论,国内也有专门讨论Go语言并发编程的书籍。读者可以根据自己的需求查阅相关的文献。
