- Web 编程基础
- 从浏览器到服务器
- HTTP 协议
- 从 HTML 到页面显示
- 从浏览器到服务器
Web 编程基础
从浏览器到服务器
如果你的操作系统带有 cURL 这个软件(在 GNU/Linux、Mac OS 都自带这个工具,Windows 用户可以从http://curl.haxx.se/download.html下载到),那么我们可以直接用下面的命令来看这看这个过程(-v 参数可以显示一次 http 通信的整个过程):
curl -v https://www.phodal.com
我们就会看到下面的响应过程:
* Rebuilt URL to: https://www.phodal.com/* Trying 54.69.23.11...* Connected to www.phodal.com (54.69.23.11) port 443 (#0)* TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384* Server certificate: www.phodal.com* Server certificate: COMODO RSA Domain Validation Secure Server CA* Server certificate: COMODO RSA Certification Authority* Server certificate: AddTrust External CA Root> GET / HTTP/1.1> Host: www.phodal.com> User-Agent: curl/7.43.0> Accept: */*>< HTTP/1.1 403 Forbidden< Server: phodal/0.19.4< Date: Tue, 13 Oct 2015 05:32:13 GMT< Content-Type: text/html; charset=utf-8< Content-Length: 170< Connection: keep-alive<<html><head><title>403 Forbidden</title></head><body bgcolor="white"><center><h1>403 Forbidden</h1></center><hr><center>phodal/0.19.4</center></body></html>* Connection #0 to host www.phodal.com left intact
我们尝试用 cURL 去访问我的网站,会根据访问的域名找出其 IP,通常这个映射关系是来源于 ISP 缓存 DNS(英语:Domain Name System)服务器[^DNSServer]。
以“*”开始的前8行是一些连接相关的信息,称为响应首部。我们向域名 https://www.phodal.com/发出了请求,接着 DNS服务器告诉了我们网站服务器的 IP,即54.69.23.11。出于安全考虑,在这里我们的示例,我们是以 HTTPS 协议为例,所以在这里连接的端口是 443。因为使用的是 HTTPS 协议,所以在这里会试图去获取服务器证书,接着获取到了域名相关的证书信息。
随后以“>”开始的内容,便是向Web服务器发送请求。Host 即是我们要访问的主机的域名,GET / 则代表着我们要访问的是根目录,如果我们要访问 https://www.phodal.com/about/页面在这里,便是 GET 资源文件 /about。紧随其后的是 HTTP 的版本号(HTTP/1.1)。User-Agent 通常指向的是使用者行为的软件,通常会加上硬件平台、系统软件、应用软件和用户个人偏好等等的一些信息。Accept 则指的是告知服务器发送何种媒体类型。
这个过程,大致如下图所示:
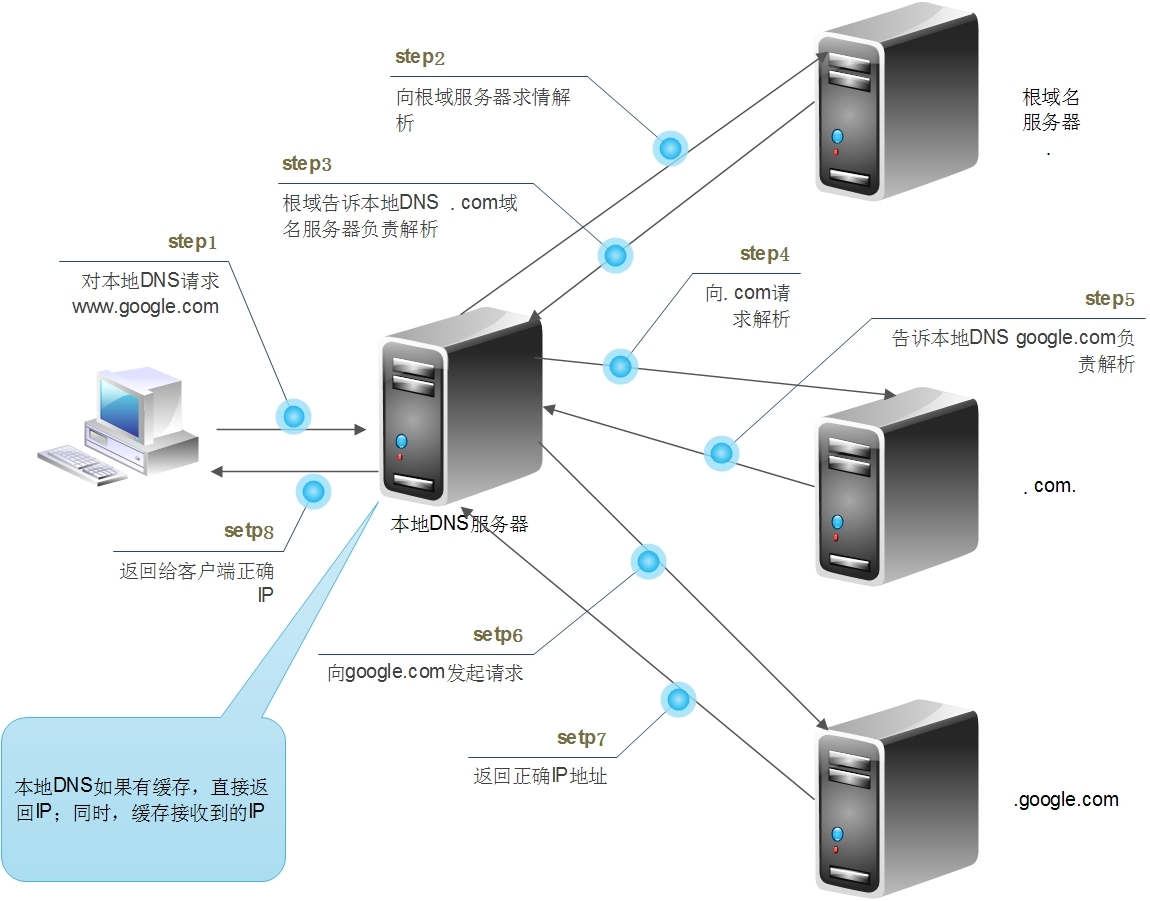
在图中,我们会发现解析 DNS 的时候,我们需要先本地 DNS 服务器查询。如果没有的话,再向根域名服务器查询——这个域名由哪个服务器来解析。直至最后拿到真正的服务器IP才能获取页面。
当我们拿到相应的 HTML、JS、CSS 后,我们就开始渲染这个页面了。
HTTP 协议
说到这里,我们不得不说说 HTTP 协议——超文本传输协议。它也是一个基于文本的传输协议,这就是为什么你在上面看到的都是文本的传输过程。
从 HTML 到页面显示
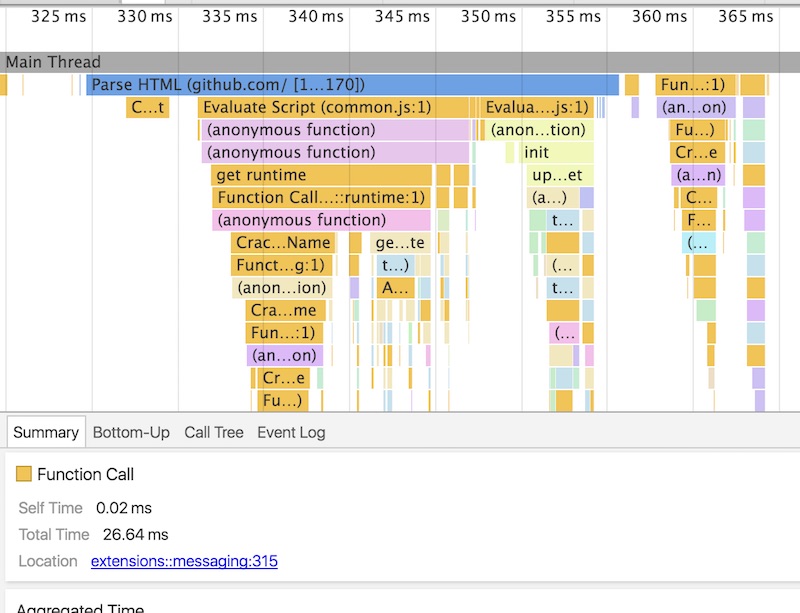
而浏览器接收到文本的时候,就要开始着手将 HTML 变成屏幕上显示的内容。下图是 Chrome 渲染页面的一个时间线:
及其整个渲染过程如下图所示:
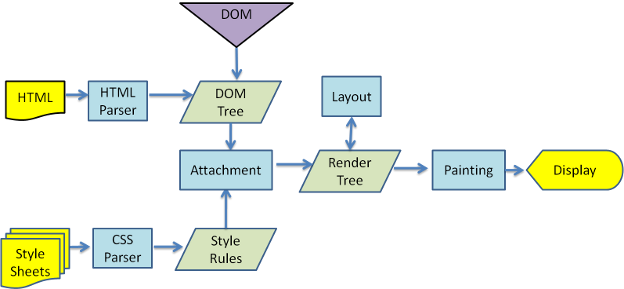
(PS: 需要注意的是这里用的是 WebKit 内核的渲染过程,即 Chrome 和 Safari 等浏览器所使用的内核。)
从上面的两图可以看出来第一步都 Parse HTML,而 Parse HTML 实质上就是将其将解析为 DOM Tree。与此同时,CSS 解析器会解析 CSS 会产生 CSS 规则树。
随后会根据生成的 DOM 树和 CSS 规则树来构建 Render Tree,接着生成 Render Tree的布局,最后就是绘制出 Render Tree。
详细的内容还得参见相关的书籍~~。
相关内容:
- 《How browsers work》
