- 数据持久化
- 文件存储
- 数据库
- ORM
- 搜索引擎
数据持久化
信息源于数据,我们在网站上看到的内容都应该是属于信息的范畴。这些信息是应用从数据库中根据业务需求查找、过滤出来的数据。
数据通常以文件的形式存储,毕竟文件是存储信息的基本单位。只是由于业务本身对于 Create、Update、Query、Index 等有不同的组合需求就引发了不同的数据存储软件。
如上章所说,View 层直接从 Model 层取数据,无遗也会暴露数据的模型。作为一个前端开发人员,我们对数据的操作有三种类型:
- 数据库。由于 Node.js 在最近几年里发展迅猛,越来越多的开发者选择使用 Node.js 作为后台语言。这与传统的 Model 层并无多大不同,要么直接操作数据库,要么间接操作数据库。即使在 NoSQL 数据库中也是如此。
- 搜索引擎。对于以查询为主的领域来说,搜索引擎是一个更好的选择,而搜索引擎又不好直接向 View 层暴露接口。这和招聘信息一样,都在暴露公司的技术栈。
- RESTful。RESTful 相当于是 CRUD 的衍生,只是传输介质变了。
- LocalStorage。LocalStorage 算是另外一种方式的 CRUD。
说了这么多都是废话,他们都是可以用类 CRUD 的方式操作。
文件存储
通常来说,以这种方式存储最常见的方式是 log(日志),如 Nginx 的 access.log。像这样的文件就需要一些专业的软件,如 GoAccess、又或者是 Hadoop、Spark 来做对应的事。
在数据库出现之前,人们都是使用文件来存储数据的。数据以文件为单位存储在硬盘上,并且这些文件不容易一起管理、修改等等。如下图所示的是我早期存储文件的一种方式:
├── 3.12│ ├── cover.png│ └── favicon.ico└── 3.13└── template.tex
每天我们都会修改、查看大量的不同类型的文件。而由于工作繁忙,我们可能没有办法一一地去分类这些文件。有时选择的便是,优先先按日期把文件一划分,接着再在随后的日子里归档。而这种存储方式大量的依赖于人来索引的工作,在很多时候往往显得不是很靠谱。并且当我们将数据存储进去后,往往很难进行修改。大量的 Log 文件就需要专门的工作来分析和使用,依赖于人来解析这些日志往往显得不是很靠谱。这时我们就需要一些重量级的工具,如用 Logstash、ElasticSearch、Kibana 来处理 Nginx 访问日志。
而对于那些非专业人员来说,使用 Excel 这样的工具往往显得比较方便。他们不需要去操作数据库,也不需要专业的知识来处理这些知识。只是从某种意义上来说,Excel 应该归属于数据库的范畴。
数据库
当我们开始一个 Web 应用的时候,如创建一个用户管理系统,我们就需要不断对文件进行查询、修改、插入和删除等操作。不仅如此,我们还需要定义数据之间的关系,如这个用户对应这个密码。在一些更复杂的情况下,我们还需要寻找这些用户中对应的一些操作数据等等。如果还是将这些工作交给文件来处理,那么我们便是在向自己挖坑。
数据库,简单来说可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
在操作库的时候,我们会使用到一名为 SQL(英语:Structural Query Language,中文: 结构化查询语言)的领域特定语言来对数据进行操作。
SQL 是高级的非过程化编程语言,它允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解其具体的数据存放方式。
数据库里存储着大量的数据,在我们对系统建模的时候,也在决定系统的基础模型。
ORM
在传统 SQL 数据库中,我们可能会依赖于 ORM,也可能会自己写 SQL。在使用 ORM 框架时,我们需要先定义 Model,如下是 Node.js 的 ORM 框架 Sequelize 的一个示例:
var User = sequelize.define('user', {firstName: {type: Sequelize.STRING,field: 'first_name'},lastName: {type: Sequelize.STRING}}, {freezeTableName: true});User.sync({force: true}).then(function () {// Table createdreturn User.create({firstName: 'John',lastName: 'Hancock'});});
上面定义的 Model,在程序初始化的时候将会创建相应的数据库字段。并且会创建一个 firstName 为 ‘John’,lastName 为 ‘Hancock’ 的用户。而这个过程中,我们并不需要操作数据库。
像 MongoDB 这类的数据库,也存在数据模型,但说的却是嵌入子文档。在业务量大的情况下,数据库在考验公司的技术能力,想想便觉得 Amazon RDS 挺好的。
搜索引擎
尽管百科上对于搜索引擎的定义是这样的:
搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
但是这样描述并不是非常准确,因为有相当多的网站采用了搜索引擎作为基础的存储服务架构,而且他们并非自动从互联网上搜索信息。搜索引擎应该分成三个部分来组成:
- 索引服务
- 搜索服务
- 索引数据
索引服务用于将数据存储到索引数据中,而搜索服务正是搜索引擎存在的意义。对于查询条件复杂的网站来说,采用搜索引擎就意味着减少了非常多的繁琐数据处理事务。在一些架构中,人们用数据库存储数据,并使用工具来将数据注入到搜索引擎中。
从架构上来说,使用搜索引擎的优点是:分离存储、查询部分。从开发上来说,它可以让我们更关注于业务本身的价值,而不是去实现这样一个搜索逻辑。
如下图所示的 Lucene 应用的架构:
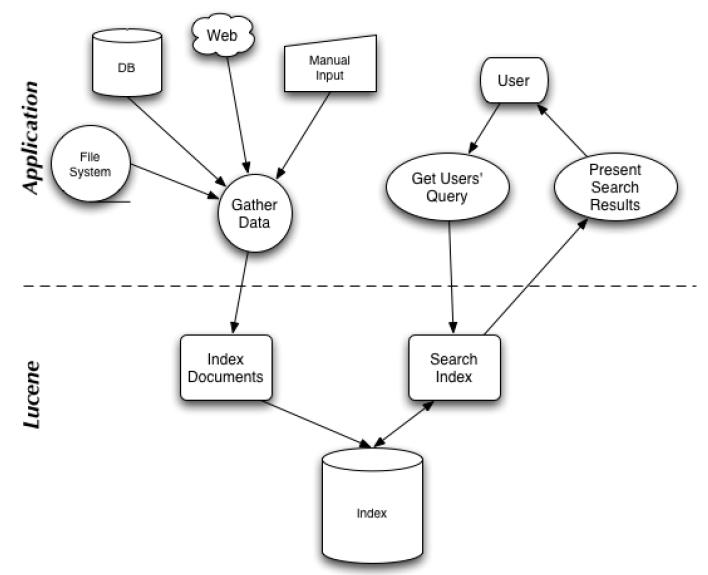
可以从图中看到系统明显被划分成两部分:
- Index Documents。索引文档部分,将用于存储数据到文件系统中。
- Search Index。搜索部分,用于查询相应的数据。
