- 添加日志收集者
- 添加 Fluentd 作为日志收集
- 添加 Kafka 作为日志收集
- 日志收集者设置
KubeSphere 提供了非常灵活的日志收集的管理配置功能,用户可以添加日志接收者包括 Elasticsearch、Kafka 和 Fluentd,甚至可以暂停 (关闭) 向某个日志接收者输出日志,也支持稍后重新启用 (激活) 该日志接收者。
在平台管理中的平台设置页面提供了日志收集配置的选项,KubeSphere 日志查询的日志是默认存在集群内部的 Elasticsearch 中。注意,生产环境强烈推荐配置外部独立的 Elasticsearch 或者 Kafka 集群来存储日志数据,添加了新的外部日志接收者后,日志查询就从这个新的日志接收者查询日志了。
添加日志收集者
以 cluster-admin 角色用户登录 KubeSphere,点击 平台管理 → 平台设置,选择 日志收集。
点击 添加日志接收者,在弹窗中可选择 Elasticsearch、Kafka 或 Fluentd 作为日志收集器。
提示:在真实环境中,如果用户想输出日志到其他地方,那么可选择将日志输出到 Fluentd,它可以通过众多的 Output 插件转发日志到非常多的地方,比如 S3, Mongodb, Cassandra, Mysql, syslog, Splunk 等等。
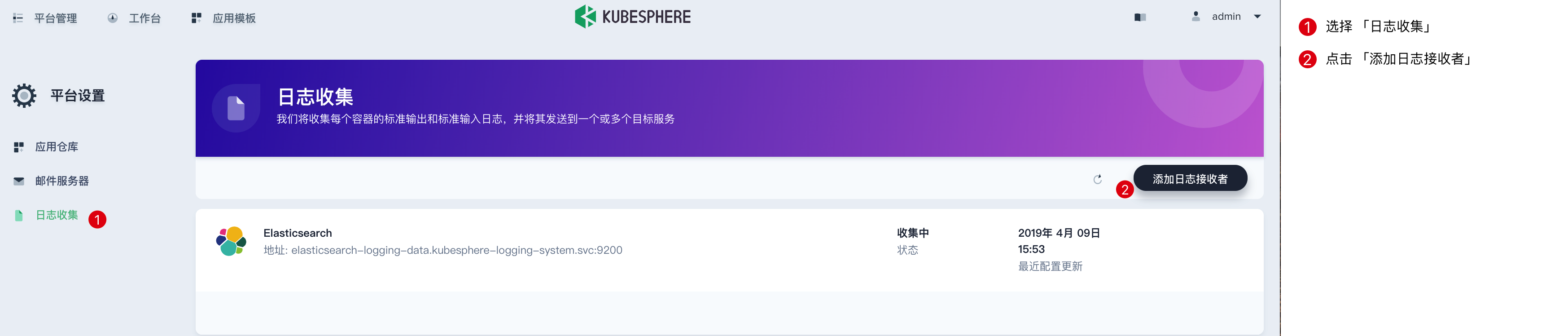
集群将内置的 Elasticsearch 作为默认的日志收集器。注意,生产环境需要配置外部独立的 Elasticsearch 或者 Kafka 集群来存储日志数据。以下分别演示添加 Fluentd 和 Kafka 作为日志收集器:
添加 Fluentd 作为日志收集
本文档演示如何在 KubeSphere 部署容器化的 Fluentd 并将其添加为日志收集者,展示 Fluentd 接收到日志数据后,输出到容器的 stdout 标准输出,参考 添加 Fluentd 作为日志收集。
添加 Kafka 作为日志收集
本文档演示如何添加 Kafka 为日志收集者,可以通过 Kafka Consumer 相关命令,验证添加日志收集者的流程是否成功,参考 添加 Kafka 作为日志收集。
日志收集者设置
点击进入 Kafka 的配置详情页,可以更改状态、删除日志收集者或编辑配置文件。

