- Angel 中的计算图
- 1. 什么是计算图
- 2. 计算图的构建
- 2.1 层的基本结构
- 2.2 AngelGraph的基本结构
- 2.3 数据入口PlaceHolder
- 3. Angel中计算图的运行原理
- 3.1 运行状态机
- 3.2 Angel中Graph的训练过程
Angel 中的计算图
1. 什么是计算图
计算图是主流深度学习框架普遍采用的, 如Tensorflow, Caffe和Mxnet等. 事实上, Spark这样的大数据处理工具也是用计算图来调度任务的. 为了更好地支持深度学习算法, Angel也支持了计算图框架. 与Tensorflow等相比, Angel的计算图更轻量, 主要表现在:
- 粗粒度: Angel的计算图中的
节点是层(layer), 而不是操作(operator). Tensorflow等使用操作作为图中的结点, 十分灵活, 适合二次开发(封装), 但也给机器学习算发开发者带来更陡的学习曲线与更大的工作量, 因此老版本的Tensorflow也一直被诟病”API太底层,开发效率低”, 后来的Tensorflow版本才提供基于层(layer)的高级API. 鉴于这一点, Angel只提供粗粒度的计算图. - 特征交叉: 对于推荐系统相关算法, 特征Embedding后往往要通过一些交叉(注:这里的特征交叉与特征工程中的人工交叉不同, 这里的特征交叉是通过Embedding的输出做特定的操作)处理后再输入DNN. 这些特征交叉在Tensorflow, Caffe, Torch等上实现比较繁锁, 在Angel上则直接提供了这种特征交叉层.
- 自动生成网络: Angel可以读取Json文件生成深度网络. 这一点是借鉴的Caffe, 用户可以不编写代码而生成自已的网络, 大大地减轻工作量.
需要指出的是, Angel目前不支持CNN, RNN等, 只关注推荐领域的常用算法.
2. 计算图的构建
2.1 层的基本结构
要了解计算图是怎样构建的, 先要了解其组成元素Layer的结构(关于层更详细的信息, 请参考Angel中的层), 如下:
abstract class Layer(val name: String, val outputDim: Int)(implicit val graph: AngelGraph)extends Serializable {var status: STATUS.Value = STATUS.Nullval input = new ListBuffer[Layer]()val consumer = new ListBuffer[Layer]()def addInput(layer: Layer): Unit = {input.append(layer)}def addConsumer(layer: Layer): Unit = {consumer.append(layer)}def calOutput(): Matrix = ???def gatherGrad(): Matrix = ???}
这个抽象类已将层的大部分功能描述清楚, 具体如下:
- status: Angel计算图中的节点是有状态的, 用一个状态机来处理, 具体在下一节中讲述
- input: 用以记录本节点/层有输入, 用一个ListBuffer表示, 一个层可以有多个输入层, 可多次调用addInput(layer: Layer)加入
- outputDim: 在Angel中最多只能有一个输出, outputDim用于指定输出的维度
- consumer: 层虽然只有一个输出, 但输出结点可以被多次消费, 因此用ListBuffer表示. 在构建图时调用input层的addConsumer(layer: Layer)告诉输出层哪些层消费了它
事实上, 构建图的具体操作在inputlayer/linearlayer/joinlayer的基类中已完成, 用户自定义layer不必关心, 如下:
abstract class InputLayer(name: String, outputDim: Int)(implicit graph: AngelGraph)extends Layer(name, outputDim)(graph) {graph.addInput(this)def calBackward(): Matrix}abstract class JoinLayer(name: String, outputDim: Int, val inputLayers: Array[Layer])(implicit graph: AngelGraph)extends Layer(name, outputDim)(graph) {inputLayers.foreach { layer =>layer.addConsumer(this)this.addInput(layer)}def calGradOutput(idx: Int): Matrix}abstract class LinearLayer(name: String, outputDim: Int, val inputLayer: Layer)(implicit graph: AngelGraph)extends Layer(name, outputDim)(graph) {inputLayer.addConsumer(this)this.addInput(inputLayer)def calGradOutput(): Matrix}
注: LossLayer是一种特殊的LinearLayer, 所以这里没有给出.
2.2 AngelGraph的基本结构
通过input/consumer构建起了一个复杂的图, 虽然可以从图中的任意节点对图进行遍历, 但是为了方便, 在AngelGraph中还是存储verge节点, 便于对图的操作, 如下:
class AngelGraph(val placeHolder: PlaceHolder, val conf: SharedConf) extends Serializable {def this(placeHolder: PlaceHolder) = this(placeHolder, SharedConf.get())private val inputLayers = new ListBuffer[InputLayer]()private var lossLayer: LossLayer = _private val trainableLayer = new ListBuffer[Trainable]()def addInput(layer: InputLayer): Unit = {inputLayers.append(layer)}def setOutput(layer: LossLayer): Unit = {lossLayer = layer}def getOutputLayer: LossLayer = {lossLayer}def addTrainable(layer: Trainable): Unit = {trainableLayer.append(layer)}def getTrainable: ListBuffer[Trainable] = {trainableLayer}
verge有两大类:
- inputLayer: 这类节点的输入是数据, AngelGraph中存储这类节点是方便反向计算, 只要依次调用inputlayer的
calBackward. 为了加入inputLayer, Angel要求所有的inputLayer中都调用AngelGraph的addInput方法将自已加入AngelGraph中. 事实上, 在InputLayer的基类中已完成这一操作, 用户新增inputLayer不必关心这一点 - lossLayer: 目前Angel不支持多任务学习, 所以只有一个lossLayer, 这类节点主要方便前向计算, 只要调用它的
predict或calOutput即可. 由于losslayer是linearlayer的子类, 所以用户自定义lossLayer可手动调用setOutput(layer: LossLayer), 但用户新增losslayer的机会不多, 更多的是增加lossfunc.
有了inputLayers, lossLayer后, 从AngelGraph中遍历图十分方便, 正向计算只要调用losslayer的predict方法, 反向计算只要调用inputlayer的calBackward. 但是梯度计算, 参数更新不方便, 为了方便参数更新, AngelGraph中增加了一个trainableLayer的变量, 用以保存带参数的层.
2.3 数据入口PlaceHolder
通过layer的input/consumer构建起了图的边(节点的关系), 在AngelGraph中保存特殊节点(inputlayer/losslayer/trainablelayer)方便前向与后向计算与参数更新. 最后数据是怎样输入的呢? — 通过PlaceHolder
Angel中的PlaceHolder在构建AngelGraph中传给Graph, 而Graph又作为隐式参数传给Layer, 所以在所有的Layer中都可以访问placeholder(即数据).
目前, Angel中只允许有一个PlaceHolder, 以后会去除这一限制, 允许多种数据输入. PlaceHolder只存放一个mini-batch的数据, 主要方法如下:
class PlaceHolder(val conf: SharedConf) extends Serializable {def feedData(data: Array[LabeledData]): Unitdef getFeats: Matrixdef getLabel: Matrixdef getBatchSize: Intdef getFeatDim: Longdef getIndices: Vector}
通过feedData, 将Array[LabeledData]类型的数据给placeholder后, 便可以从其中获得:
- 特征
- 特征维度
- 标签
- batchSize
- 特征索引
3. Angel中计算图的运行原理
上一节中构建起了计算图的拓朴结构, 这一节要讲述它是怎样运行的
3.1 运行状态机
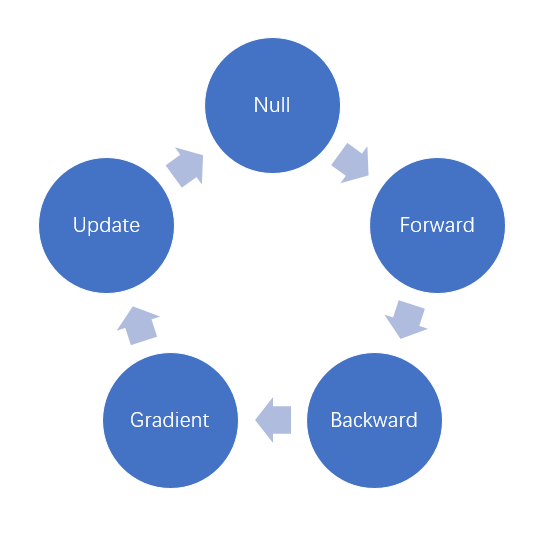
Angel的状态机有如下几个状态:
- Null: 初始状态, 每次feedData后都会将Graph置于这一状态
- Forward: 这一状态表示前向计算已完成
- Backward: 这一状态表示后向计算已完成, 但还没有计算参数的梯度
- Gradient: 这一状态表示梯度已计算完成, 并且梯度已推送到PS上了
- Update: 这一状态表示模型更新已完成
这些状态是依次进行的, 如下图所示:
状态机的引入主要是保证运算的顺序进行, 减少重复计算. 例如有多个层消费同一层的输出, 在计算时, 可以根所据状态进行判断, 只要计算一次. 状态机在代码中的体现为:
def feedData(data: Array[LabeledData]): Unit = {deepFirstDown(lossLayer.asInstanceOf[Layer])((lay: Layer) => lay.status != STATUS.Null,(lay: Layer) => lay.status = STATUS.Null)placeHolder.feedData(data)}override def calOutput(): Matrix = {status match {case STATUS.Null =>// do come forward calculationstatus = STATUS.Forwardcase _ =>}output}override def calBackward(): Matrix = {status match {case STATUS.Forward =>val gradTemp = gatherGrad()// do backward calculationstatus = STATUS.Backwardcase _ =>}backward}override def pushGradient(): Unit = {status match {case STATUS.Backward =>// calculate gradient and push to PSstatus = STATUS.Gradientcase _ =>}}override def update(epoch: Int = 0): Unit = {status match {case STATUS.Gradient =>optimizer.update(weightId, 1, epoch)status = STATUS.Updatecase _ =>throw new AngelException("STATUS Error, please calculate Gradient frist!")}}
3.2 Angel中Graph的训练过程
具体的代码在GraphLearner, 这理给出框架,
def trainOneEpoch(epoch: Int, iter: Iterator[Array[LabeledData]], numBatch: Int): Double = {var batchCount: Int = 0var loss: Double = 0.0while (iter.hasNext) {graph.feedData(iter.next())graph.pullParams()loss = graph.calLoss() // forwardgraph.calBackward() // backwardgraph.pushGradient() // pushgradPSAgentContext.get().barrier(ctx.getTaskId.getIndex)if (ctx.getTaskId.getIndex == 0) {graph.update(epoch * numBatch + batchCount) // update parameters on PS}PSAgentContext.get().barrier(ctx.getTaskId.getIndex)batchCount += 1LOG.info(s"epoch $epoch batch $batchCount is finished!")}loss}
步骤如下:
- feedData: 这个过程会将Graph的状态设为Null
- 拉取参数: 会根据数据, 只拉取当前mini-batch计算所需要的参数, 所以Angel可以训练非常高维的模型
- 前向计算: 从Losslayer开始, 级联地调用它的inputlayer的
calOutput方法, 依次计算output, 计算完后将它的状态设为forward. 对于状态已是forward的情况, 则直接返回上一次计算的结果, 这样避免重复计算 - 后向计算: 依次调用Graph的inputlayer, 这样会级联调用第一层的
CalGradOutput方法, 完成后向计算. 计算完后将它的状态设为backward. 对于状态已是backward的情况, 则直接返回上一次计算的结果, 这样避免重复计算 - 梯度计算与更新: 计算
backward只计算了网络结点的梯度, 并没有计算参数的梯度. 这一步计算参数的梯度, 只需调用trainable的pushGradient即可. 这个方法会先计算梯度, 然后再将梯度推送到PS上, 最后将状态设为gradient - 梯度更新: 梯度更新是在PS上进行的, 只要发送一个梯度更新的PSF即可, 因此只需一个Workor发送(在Spark on Angel中是通过Driver发送). 不同的优化器的更新方式不一样, 在Angel中, 优化器的核心本质是一个PSF. 参数更新前要做一次同步, 保证所有的梯度都推送完成, 参数更新完成也要做一次同步, 保证所有worker拉取的参数是最新的. 参数更新完成状态被设成
update
