- Angel中的优化器
- 1. SGD
- 2. Momentum
- 3. AdaGrad
- 4. AdaDelta
- 5. Adam
- 4. FTRL
Angel中的优化器
机器学习的优化方法多种多样, 但在大数据场景下, 使用最多的还是基于SGD的一系列方法. 在Angel中目前只实现了少量的最优化方法, 如下:
- 基于随机梯度下降的方法
- SDG: 这里指mini-batch SGD (小批量随机梯度下降)
- Momentum: 带动量的SGD
- AdaGrad: 带Hessian对角近似的SGD
- AdaDelta:
- Adam: 带动量与对角Hessian近似的SGD
- 在线学习方法
- FTRL: Follow The Regularized Leader, 一种在线学习方法
1. SGD
SGD的更新公式如下:
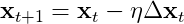
其中, 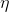 是学习率. 使用SGD可以带
是学习率. 使用SGD可以带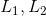 正则, 实际优化采用的是PGD(proximal gradient descent).
正则, 实际优化采用的是PGD(proximal gradient descent).
json方式表达有两种, 如下:
"optimizer": "sgd","optimizer": {"type": "sgd","reg1": 0.01,"reg2": 0.02}
2. Momentum
Momentum的更新公式如下:
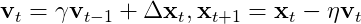
其中, 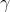 是动量因子, 是学习率. 另外, Momentum也是可以带
是动量因子, 是学习率. 另外, Momentum也是可以带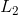 正则的. Angel中默认的最优化方法为Momentum.
正则的. Angel中默认的最优化方法为Momentum.
json方式表达有两种, 如下:
"optimizer": "momentum","optimizer": {"type": "momentum","momentum": 0.9,"reg2": 0.01}
3. AdaGrad
AdaGrad(这里用的是指数平滑版, 即RMSprop)的更新公式如下:
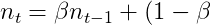 g_{t}^2)
g_{t}^2)
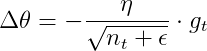
其中, 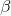 是平滑因子, 是学习率. 另外, AdaGrad也是可以带
是平滑因子, 是学习率. 另外, AdaGrad也是可以带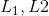 正则的.
正则的.
json方式表达有两种, 如下:
"optimizer": "adagrad","optimizer": {"type": "adagrad","beta": 0.9,"reg1": 0.01,"reg2": 0.01}
4. AdaDelta
AdaDelta的更新公式如下:
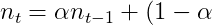 g_{t}^2)
g_{t}^2)
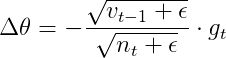
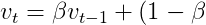 \Delta%20\theta_{t}^2)
\Delta%20\theta_{t}^2)
其中, 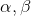 是平滑因子. AdaDelta也是可以带正则的.
是平滑因子. AdaDelta也是可以带正则的.
json方式表达有两种, 如下:
"optimizer": "adadelta","optimizer": {"type": "adadelta","alpha": 0.9,"beta": 0.9,"reg1": 0.01,"reg2": 0.01}
5. Adam
Adam是一种效果较好的最优化方法, 更新公式为:
 \Delta\bold{x}t\\\bold{v}_t&=\gamma\bold{v}{t-1}+(1-\gamma)\Delta\bold{x}^2t\\\bold{x}_t&=\gamma\bold{x}{t-1}-\eta\frac{\sqrt{1-\gamma^t}}{1-\beta^t}\frac{\bold{m}_t}{\sqrt{\bold{v}_t}+\epsilon}\%20\end{array})
\Delta\bold{x}t\\\bold{v}_t&=\gamma\bold{v}{t-1}+(1-\gamma)\Delta\bold{x}^2t\\\bold{x}_t&=\gamma\bold{x}{t-1}-\eta\frac{\sqrt{1-\gamma^t}}{1-\beta^t}\frac{\bold{m}_t}{\sqrt{\bold{v}_t}+\epsilon}\%20\end{array})
其中, 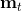 是梯度
是梯度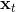 的指数平滑, 即动量,
的指数平滑, 即动量, 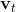 是梯度
是梯度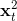 的指数平滑, 可以看作Hessian的对角近似. 默认情况下
的指数平滑, 可以看作Hessian的对角近似. 默认情况下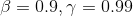 , 记
, 记
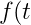 =\frac{\sqrt{1-\gamma^t}}{1-\beta^t})
=\frac{\sqrt{1-\gamma^t}}{1-\beta^t})
则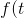 )是一个初值为1, 极限为1的函数, 中间过程先减后增, 如下图所示:
)是一个初值为1, 极限为1的函数, 中间过程先减后增, 如下图所示: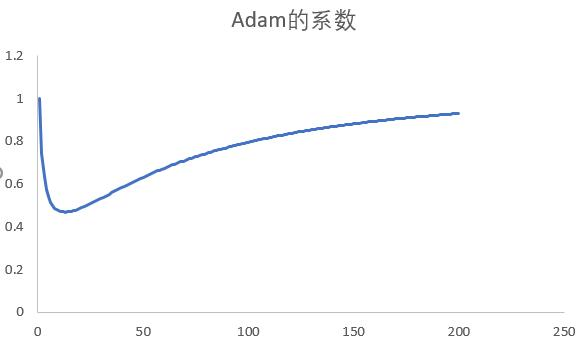
即在优化的初始阶段, 梯度较大, 适当地减小学习率, 让梯度下降缓和平滑; 在优化的最后阶段, 梯度很小, 适当地增加学习率有助于跳出局部最优.
json方式表达有两种, 如下:
"optimizer": "adam","optimizer": {"type": "adam","beta": 0.9,"gamma": 0.99,"reg2": 0.01}
4. FTRL
FTRL是一种在线学习算法, 它的目标是优化regret bound, 在一定的学习率衰减条件下, 可以证明它是有效的.
FTRL的另一个特点是可以得到非常稀疏的解, 表现上比PGD(proximal gradient descent)好, 也优于其它在线学习算法, 如FOBOS, RDA等.
FTRL的算法流程如下:

json方式表达有两种, 如下:
"optimizer": "ftrl","optimizer": {"type": "ftrl","alpha": 0.1,"beta": 1.0,"reg1": 0.01,"reg2": 0.01}
注: 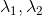 是正则化常数, 对应json中的”reg1, reg2”
是正则化常数, 对应json中的”reg1, reg2”
一些经验:
对于deep and wide算法, 原则上要保证两边收敛速度相差不要太大.
- wide部分优化器用FTRL, 因为FTRL收敛相对较慢, 这样有深度那边训练.
- deep部分优化器用Adam, 因为Adam收敛相对较快. 虽然deep侧用的是快速收敛优化器, 但他的参数多
对于FTRL优化器, 它为在线学习设计, 为了保证模型的稳定性, 每次更新的副度都非常小. 在在线学习环境下, 数据是一条一条或一小批一小批, 在理论上也不应让小量数据较多地修改模型. 所以在用FTRL算法是, batch size不能太大, 最好小于10000条数据.
不同的优化器收敛速度关系: FTRL < SGD < Momentum < AdaGrad ~ AdaDelta < Adam
由于AdaGrad, AdaDelta, Adam引入了Hessian对角近似, 它们可以有较大的batch, 以保证梯度与Hessian对角矩阵的精度. 而对于FTRL, SGD, Momentum等较为简单的一阶优化器, 它们则需要更多的迭代次数, 因些batch size不能太大. 所以有:BatchSize(FTRL) < BatchSize(SGD) < BatchSize(Momentum) < BatchSize(AdaGrad) ~ BatchSize(AdaDelta) < BatchSize(Adam)
关于学习率, 可以从1.0开始, 以指数的方式(2或0.5为底)增加或减少. 可以用learning curve进行early stop. 但有如下原则: SGD, Momentum可以用相对较大的学习率, AdaGrad, AdaDelta, Adam对学习率较敏感, 一般讲比SGD, Momentum小, 可从SGD, Momentum学习率的一半开始调
关于Decay, 如果epoch较少, decay不宜过大. 一般用标准的decay, AdaGrad, AdaDelta, Adam用WarnRestarts
关于正则化. 目前FTRL, SGD, AdaGrad, AdaDelta支持L1/L2正则, Momentum, Adam只支持L2正则. 推荐从不用正则开始, 然后再加正则.
关于加L1正则的推导, 请参考optimizer
