- Word2Vec
- 1. 算法介绍
- 2. 分布式实现
- 运行
- 算法IO参数
- 算法参数
Word2Vec
Word2Vec算法是NLP领域著名的算法之一,可以从文本数据中学习到单词的向量表示,并作为其他NLP算法的输入。
1. 算法介绍
开发Word2Vec模块的初衷是实现另一个常用的Network Embedding算法——Node2Vec算法。 Node2Vec算法分两个阶段:
网络随机游走
使用Word2Vec算法跑随机游走得到的序列
由于用Angel实现网络随机游走没有特别突出的优点,我们这里只提供了第二阶段工作的实现。特别的,如果替换第一阶段的随机游走算法,将得到不同的Network Embedding算法。
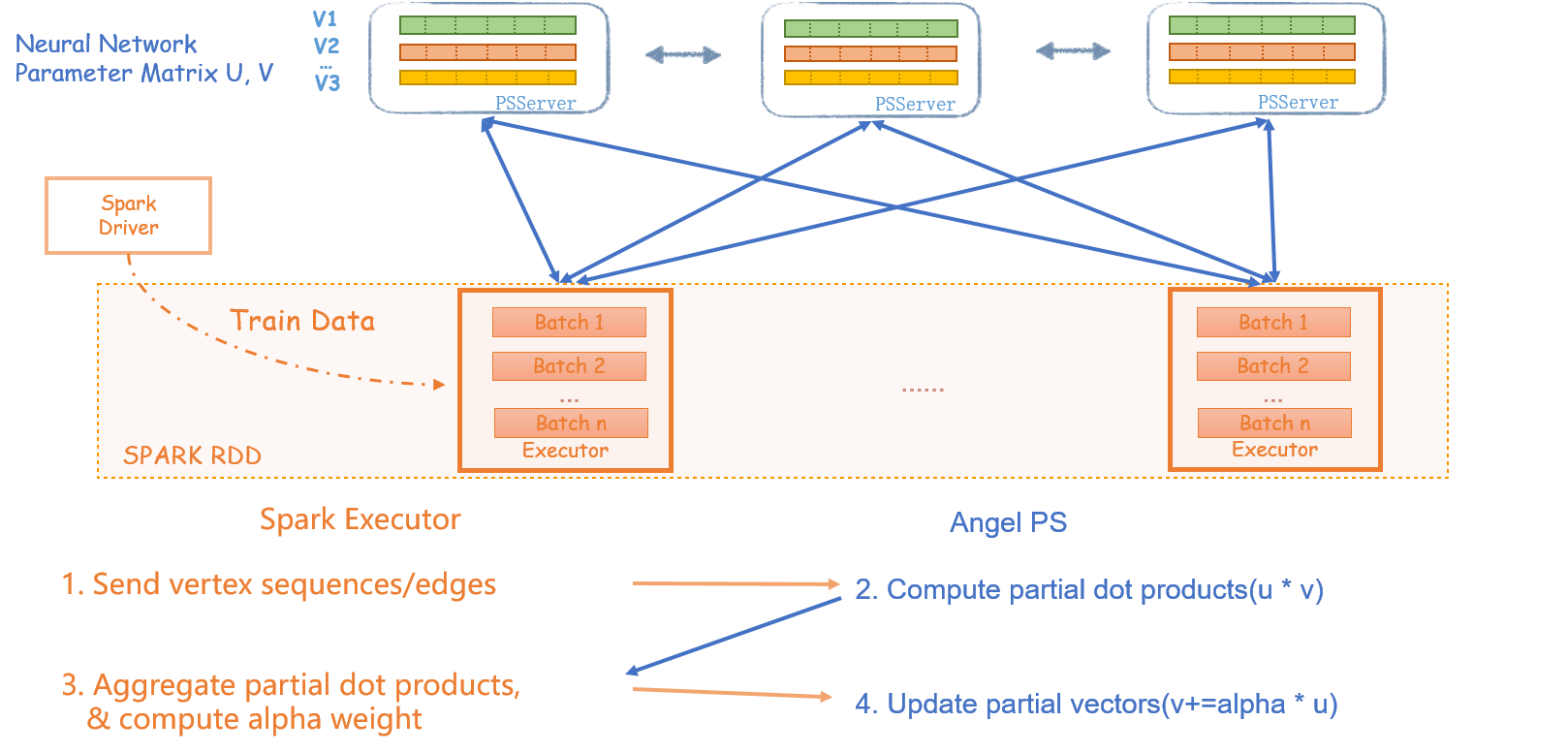
2. 分布式实现
由于图表示学习使用的Word2Vec算法需要能够处理超大的词库(可以轻易达到10亿),纯粹基于Spark的实现的模块无法支撑这种规模的数据。这里依靠Spark On Angel的PS能力,能够处理高达10亿 * 1000维的超大模型。 Word2Vec的理论网上有大量的资料可以参考,这里实现了基于负采样优化的SkipGram模型。 超大规模的分布式实现参考了Yahoo的论文[1]。
运行
算法IO参数
- input: hdfs路径,随机游走出来的sentences,word需要从0开始连续编号,以空白符或者逗号分隔,比如:
0 1 3 5 92 1 5 1 73 1 4 2 83 2 5 1 34 1 2 9 4
- modelPath: hdfs路径, 最终的模型保存路径为hdfs:///…/epoch_checkpoint_x,其中x代表第x轮epoch
- modelCPInterval: 每隔多少轮epoch保存一次模型
算法参数
- vectorDim: 嵌入的向量空间维度,即为embedding向量和context的向量维度 - 负采样数: 算法采样的是负采样优化,表示每个pair使用的负采样节点数
- learningRate: 学习率很影响该算法的结果,太高很容易引起模型跑飞的问题,如果发现结果量级太大,请降低该参数
- BatchSize: 每个mini batch的大小
- maxEpoch: 样本使用的轮数,每轮结束之后样本会shuffle一遍
window: 训练的窗口大小,使用前window/2与后window/2的词
常见问题
- 在差不多10min的时候,任务挂掉: 很可能的原因是angel申请不到资源!由于LINE基于Spark On Angel开发,实际上涉及到Spark和Angel两个系统,它们的向Yarn申请资源是独立进行的。 在Spark任务拉起之后,由Spark向Yarn提交Angel的任务,如果不能在给定时间内申请到资源,就会报超时错误,任务挂掉! 解决方案是: 1)确认资源池有足够的资源 2) 添加spark conf: spark.hadoop.angel.am.appstate.timeout.ms=xxx 调大超时时间,默认值为600000,也就是10分钟
- 如何估算我需要配置多少Angel资源: 为了保证Angel不挂掉,需要配置模型大小两倍左右的内存。 模型大小的计算公式为: 节点数 Embedding特征的维度 8 Byte,比如说1kw节点、100维的配置下,模型大小差不多有60G大小,那么配置instances=4, memory=30就差不多了。 另外,在可能的情况下,ps数目越小,数据传输的量会越小,但是单个ps的压力会越大,需要一定的权衡。
- Spark的资源配置: 同样主要考虑内存问题,最好能存下2倍的输入数据。 如果内存紧张,1倍也是可以接受的,但是相对会慢一点。 在资源实在紧张的情况下, 尝试加大分区数目!
