- LDA*(Latent Dirichlet Allocation)
- 1. 算法介绍
- 整体说明
- Gibbs Sampling
- Collapsed Gibbs Sampling
- F+LDA
- 2. 分布式训练 on Angel
- 3. 运行 & 性能
- Reference
- 1. 算法介绍
LDA*(Latent Dirichlet Allocation)
LDA是一种常见的主题模型算法。简单来说它是一个贝叶斯概率生成模型,用于对文档集进行降维或者潜在语义分析。
1. 算法介绍
整体说明
给定一个语料库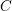 ,该语料库由一系列文档
,该语料库由一系列文档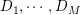 构成。每个文档
构成。每个文档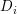 则由一个序列的词构成,
则由一个序列的词构成,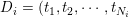 )。语料库中的词整体构成了一个词汇表
)。语料库中的词整体构成了一个词汇表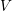 。LDA模型需要人为指定模型的话题个数,这里用
。LDA模型需要人为指定模型的话题个数,这里用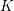 来表示。在LDA模型中,每个文档被表示成了一个维的话题分布,
来表示。在LDA模型中,每个文档被表示成了一个维的话题分布,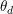 ,而每个话题
,而每个话题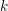 则被表示成一个维的词分布
则被表示成一个维的词分布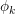 。
。
LDA模型对每个文档的生成过程进行了建模。在文档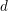 的生成过程中,LDA首先从狄利克雷分布
的生成过程中,LDA首先从狄利克雷分布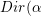 )中采样出一个维的话题分布,这里的
)中采样出一个维的话题分布,这里的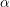 是狄利克雷分布的超参数。对于文档中的每个词
是狄利克雷分布的超参数。对于文档中的每个词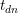 ,LDA模型首先从多项分布
,LDA模型首先从多项分布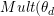 )中采样出该词的话题
)中采样出该词的话题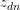 ,然后再从多项分布
,然后再从多项分布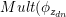 )中采样出单词
)中采样出单词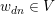 。
。
Gibbs Sampling
求解LDA模型的过程通常使用Gibbs Sampling方法,通过采样出大量符合后验分布的样本,从而对每个文档的话题分布和话题的词分布进行估计估计。目前对LDA的Gibbs Sampling方法有大概6中,包括 Collapsed Gibbs Sampling(CGS), SparseLDA,AliasLDA, F+LDA, LightLDA和WarpLDA。我们通过实验和分析, 认为F+LDA比较适合用于在Angel上进行LDA模型的训练。
Collapsed Gibbs Sampling
如果我们使用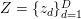 来表示所有词的话题,用
来表示所有词的话题,用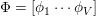 来表示维度为
来表示维度为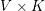 的话题-词矩阵,用
的话题-词矩阵,用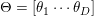 来表示所有文档的话题分布矩阵。那LDA模型的训练过程则是在给定观测变量
来表示所有文档的话题分布矩阵。那LDA模型的训练过程则是在给定观测变量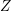 和超参数的条件下,求解隐变量
和超参数的条件下,求解隐变量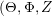 )的后验概率分布。CGS通过分布之间共轭的性质将
)的后验概率分布。CGS通过分布之间共轭的性质将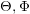 通过积分积掉,从而CGS只用迭代地采样每个词的话题。采样的条件概率公式如下:
通过积分积掉,从而CGS只用迭代地采样每个词的话题。采样的条件概率公式如下:
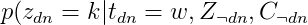 \propto\frac{C{wk}^{\neg%20dn}+\beta}{C{k}^{\neg%20dn}+V\beta}~(C_{dk}^{\neg%20dn}+\alpha))
\propto\frac{C{wk}^{\neg%20dn}+\beta}{C{k}^{\neg%20dn}+V\beta}~(C_{dk}^{\neg%20dn}+\alpha))
F+LDA
F+LDA通过将概率公式进行了分解成两部分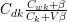 和
和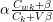 。利用
。利用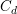 矩阵的稀疏性,从而在采样时可以只用访问非零的部分,降低了算法的复杂度。对于另一个部分,F+LDA采用F+树来进行查找,可以将复杂度降低到O(logK)。从而F+LDA的复杂度为
矩阵的稀疏性,从而在采样时可以只用访问非零的部分,降低了算法的复杂度。对于另一个部分,F+LDA采用F+树来进行查找,可以将复杂度降低到O(logK)。从而F+LDA的复杂度为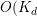 ),
),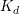 是文档-话题矩阵中非零元素的个数。
是文档-话题矩阵中非零元素的个数。
2. 分布式训练 on Angel
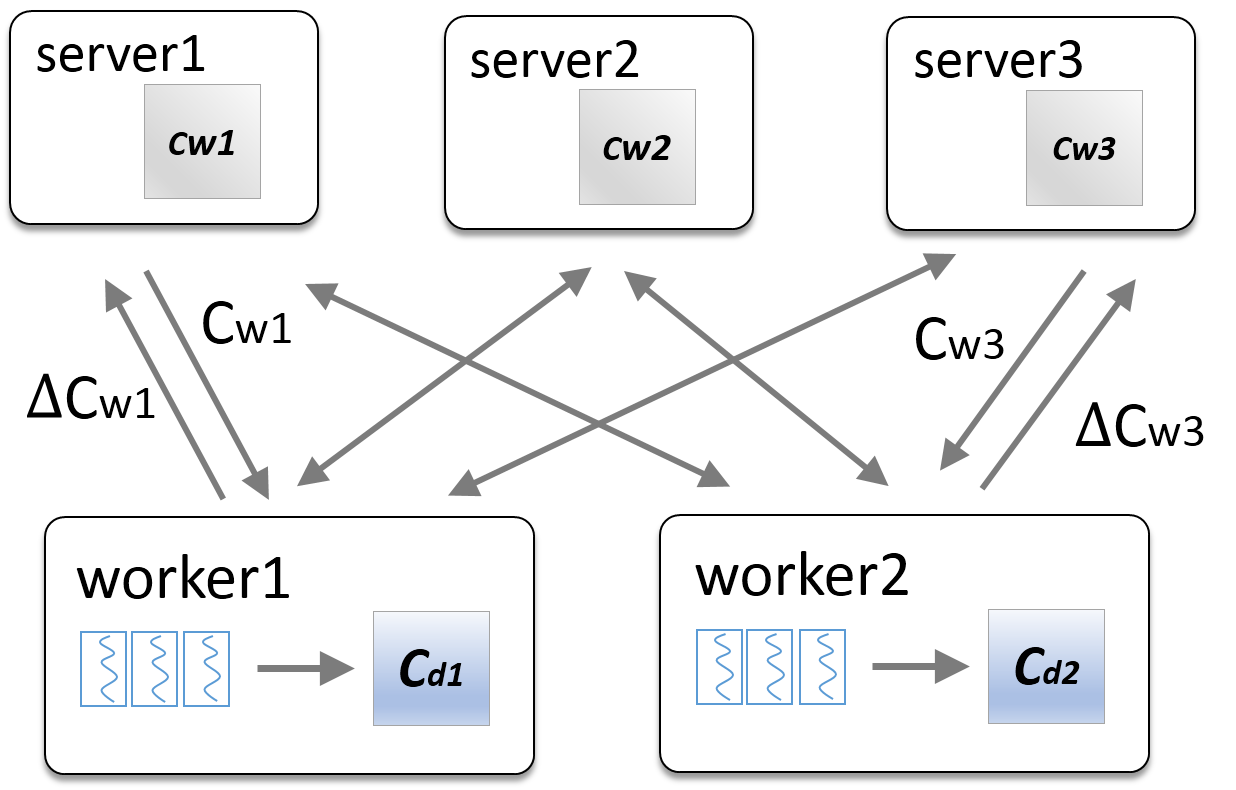
在Angel中进行LDA模型的训练,整体的框架如下图所示。对于LDA模型中的两个较大的矩阵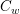 和,我们将C_d矩阵划分到不同的worker上,将C_w矩阵划分到不同的server上。在每一轮迭代中,worker从server上拉取C_w矩阵,从而进行话题的采样,在迭代结束时将对C_w矩阵的更新发送回server节点。
和,我们将C_d矩阵划分到不同的worker上,将C_w矩阵划分到不同的server上。在每一轮迭代中,worker从server上拉取C_w矩阵,从而进行话题的采样,在迭代结束时将对C_w矩阵的更新发送回server节点。
3. 运行 & 性能
- 输入格式
输入数据分为多行,每行是一个文档,每个文档的第一个部分是文档的ID,文档的ID可以是字符串或者数字;文档ID后紧跟一个\t字符,然后由一系列的词id构成,词id之间由空格隔开
docId\twid_0 wid_1 ... wid_n
模型训练
输入
- angel.train.data.path: 输入数据路径
- angel.save.model.path: 模型保存路径
输出配置
- save.doc.topic=true: 是否保存doc-topic矩阵
- save.word.topic=true: 是否保存word-topic矩阵
- save.doc.topic.distribution=true: 是否保存doc.topic分布
- save.topic.word.distribution=true: 是否保存topic.word分布
算法参数
- ml.epoch.num: 算法迭代次数
- ml.lda.word.num:词个数
- ml.lda.topic.num:话题个数
- ml.worker.thread.num:worker内部并行度
- ml.lda.alpha: alpha参数
- ml.lda.beta: beta参数
结果预测
- 输入与输出
- angel.predict.data.path:预测数据的输入路径
- angel.predict.out.path:预测结果存储路径
- angel.load.model.path: 预测时模型加载路径(即训练时模型保存路径)
- 输入与输出
注意事项
- 目前angel lda上的输出需要对词语进行编号,最好保证编号从0开始,并且连续,输入文件中需要将文档中的词语换成编号。词语到编号的映射关系需要用户自行维护。
参数说明
- 输入输出路径均为HDFS路径
- 预测是需要给定话题个数与训练时需相同,预测时需要给定最大word ID,或者给一个较大的值,保证能覆盖所有词语ID。
输出格式说明
- doc-topic矩阵:每行是一个文档,格式为libsvm格式,第一个元素是文档id,后面每一个key:value表示该文档中有多少个词语(value)赋予到了话题(key)。Angel中采用吉布斯采样来求解LDA,本质即是为每个词语赋予话题,用于可以根据根据该矩阵估计每个文档中的话题分布。
- doc.topic.distribution: 每行是一个文档,格式为libsvm格式,第一个元素是文档id,后面每一个key:value表示每个话题的概率。这里的概率即根据doc-topic矩阵算出,具体的公式可参看LDA原文。我们这里只给出了上述非零赋值的话题概率,剩余每个话题的概率相等,可以自行算出。
- word-topic: 每行是一个词语,格式为libsvm,第一个元素是word id,后面每一个key:value表示在该词语的所有出现中,每个话题(key)分配到了多少个词语(value)。word-topic是预测时必须的参数,如要进行预测,请保存word-topic。一般根据word-topic,可以估计出每个word在话题上的分布。如果发现一些word没有话题分配信息,是因为这个词语在整个文档集中没有出现。
- topic.word.distribution: 每行是一个话题,格式为libsvm,第一个元素是topic id,后面的key:value表示每个话题在词语集合上的概率分布。我们这里也只给出了非零赋值的概率,剩余的词语概率相等,可以自行算出。
性能
- 测试数据
PubMED 数据集
资源
- worker:20个
ps:20个
Angel vs Spark: 迭代100次的训练时间
- Angel:15min
- Spark:>300min
Reference
- Lele Yu, Bin Cui, Ce Zhang, Yingxia Shao. LDA*: A Robust and Large-scale Topic Modeling System. VLDB, 2017
