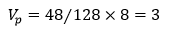- Angel资源配置指南
- Master
- Worker资源
- 1. Worker个数预估
- 2. Worker内存预估
- 3. Worker CPU VCore数预估
- PS资源
- 1. PS个数预估
- 2. PS内存预估
- 3. PS CPU VCore个数预估
- Logistic Regression参数配置
Angel资源配置指南
Angel是基于PS范式的分布式机器学习系统。Parameter Server的引入,简化了计算模型的复杂度,提升了运行速度。但是,一个额外系统的引入,也造成了资源的配置复杂度增加。为此,我们编写了该指南,希望能帮助Angel的用户,更好的配置出高性能的PS系统,跑出高性能的算法。
运行一个Angel任务,需要确定任务的资源参数如下。根据你的数据大小,模型设计,机器学习算法,准确预估出所需要的资源,将能大大提升运行效率。
- Master
- Master的内存大小
- Master的CPU VCore
- Worker
- Worker的个数
- 单个Worker的内存大小
- 单个Worker的CPU VCore
- Parameter Server
- PS个数
- 单个PS内存大小
- 单个PS需要的CPU VCore
Master
由于Angel的Master非常轻量,大部分情况下,使用默认参数就可以满足要求了,所以我们主要需要配置的是Worker和PS的资源参数。 计算不会发生在Master端,除非Worker数非常多,才需要稍微调大Master资源。
Worker资源
1. Worker个数预估
为了更好的实现数据并行,Angel可以自由配置Worker的个数。一般情况下,Worker的个数主要取决于总的需要计算的数据量大小。一般情况下,单个Worker处理的数据量推荐值为1-5GB(这里特指未压缩的文本格式数据,其他格式需要乘以对应的压缩比,下同)。
2. Worker内存预估
Worker的内存使用分布状况如下:
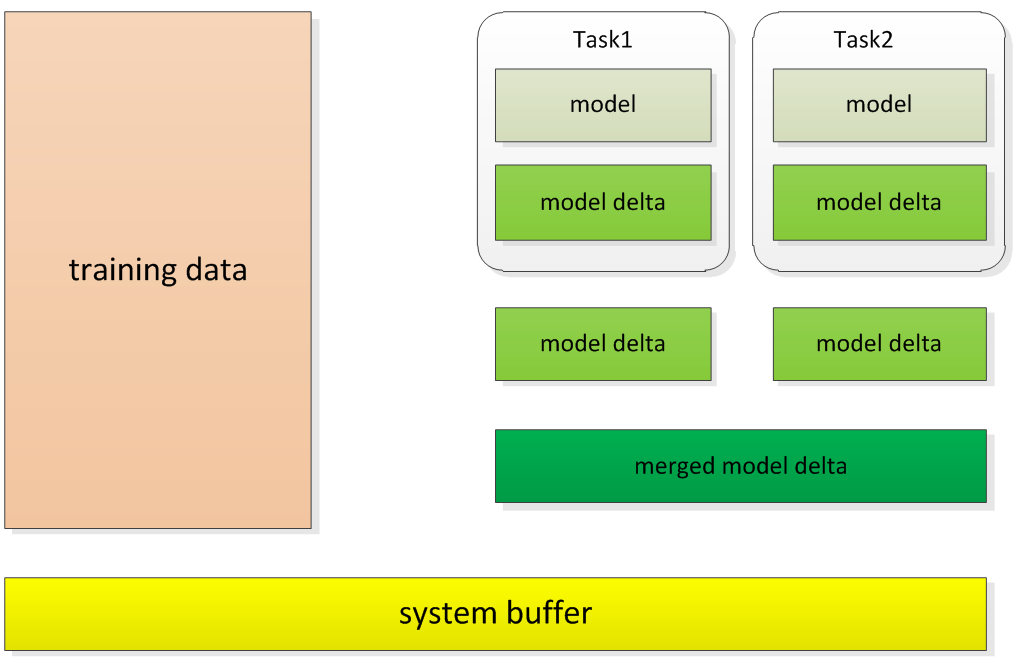
- 模型部分
- 模型(model):从PS拉取的当前Worker需要计算的模型部分
- 模型更新(model delta):Worker的Task计算得到的模型更新
- 合并后的模型更新(merged model delta):合并后的模型更新
系统部分
- 系统(system buffer):Netty框架使用的ByteBuf pool等
数据部分
- 格式化后的训练数据(training data)
- 比例:原始训练数据大小和格式化后占用内存空间的比率为1.5:1,即1.5GB的原始训练数据经格式化并加载到内存中后占用1GB的内存空间
- dummy和libsvm格式的比例相同
- 当然,如果内存紧张,可以使用本地磁盘来存储格式化的数据
- 格式化后的训练数据(training data)
计算公式
定义如下变量:
- 一个Worker上运行的Task数量为
N - 训练使用的模型部分的大小为
Sm - task每轮迭代产生的更新大小为
Smd - 合并后的模型更新大小为
Smmd - 训练数据占用的内存大小为
St 系统部分占用内存大小为
SbWorker内存估算公式为:
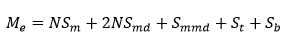
系统使用的内存可以通过下面的方法简单估算:
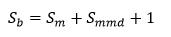
估算公式可以简化为:
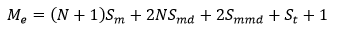
- 一个Worker上运行的Task数量为
3. Worker CPU VCore数预估
与内存参数不一样的是CPU vcore只会影响任务执行效率,而不会影响任务的正确性。建议CPU vcore数和和内存参数按物理机器资源比例来调整。举一个简单的例子:
如果一台物理机器总的内存大小是100G,CPU vcore总数为50,当Worker内存配置为10G/20G时,CPU vcore可以配置为5/10。
PS资源
1. PS个数预估
PS个数配置主要取决于Worker个数,模型的格式,和模型大小相关。
一般Worker数量越多,模型越大,需要的PS个数越多。推荐PS个数为Worker个数的1/5-4/5。PS个数和算法相关性非常大,应具体算法具体分析。
2. PS内存预估
PS的内存使用分布如下: 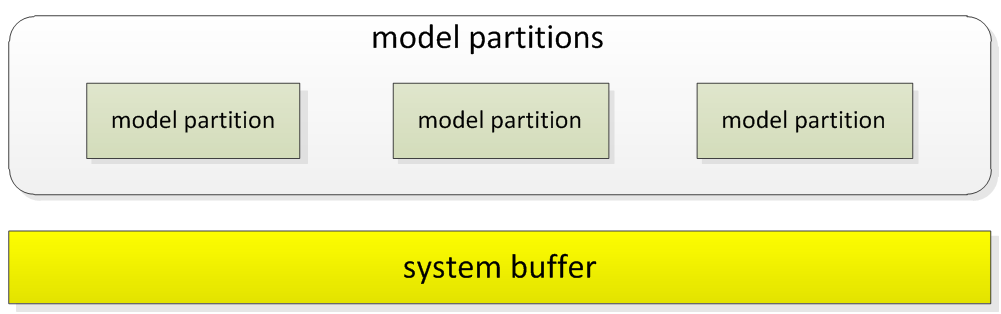
模型部分(model partitions):每个PS会加载的模型分区
- 模型的格式有稀疏和稠密两种,稀疏模型用Map,稠密模型用Double,占用的空间都不一致
系统部分(system buffer):Netty框架使用的ByteBuf pool等
- 由于要与多个Worker发生大数据量的交互,需要大量的发送和接收缓冲区。因此,一般情况下系统本身消耗的内存远大于模型分区本身。
定义如下变量
- 模型分区大小为
Smp - Task每轮迭代需要获取的模型部分大小为
Sw Worker个数为
N可以通过下面方式简单估算PS所需内存:
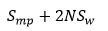
- 模型分区大小为
3. PS CPU VCore个数预估
PS CPU VCore个数估算方法与Worker一致,但是具体需要根据算法来判断。如果有些算法,大量的计算发生在PS端,那么VCore需要稍微大点。
Logistic Regression参数配置
下面以LR为例,介绍一下Angel配置的方法。默认情况下,LR的模型是一个稠密的,以Double数组来存储模型和模型的分区。
假设LR的训练数据为300GB, 模型维度为1亿,
- Worker端
配置100个Worker,每个Worker执行的Task数量为1,每个Worker需要的内存估算如下:
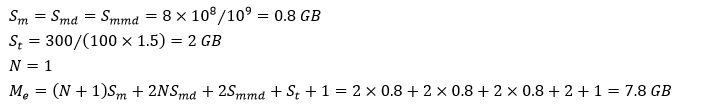
Worker内存向上取整为8GB。PS个数为Worker个数的1/5, 即20个,一个PS上承载的模型分区大小为500万, 每个PS需要的内存为:
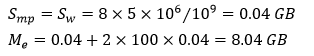
- PS端
PS内存取整为8GB
假设每一台物理机器内存为128GB, CPU vcore总数为48个, 则Worker的CPU vcore数为:
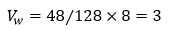
PS 的CPU vcore数为: