- 9.2 Boosting
9.2 Boosting
Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting族算法最著名、使用最为广泛的就是AdaBoost,因此下面主要是对AdaBoost算法进行介绍。AdaBoost使用的是指数损失函数,因此AdaBoost的权值与样本分布的更新都是围绕着最小化指数损失函数进行的。看到这里回想一下之前的机器学习算法,不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数:如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是log-Loss,那就是Logistic Regression了。
定义基学习器的集成为加权结合,则有:
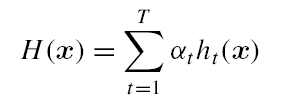
AdaBoost算法的指数损失函数定义为:
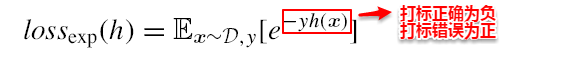
具体说来,整个Adaboost 迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
整个AdaBoost的算法流程如下所示:

可以看出:AdaBoost的核心步骤就是计算基学习器权重和样本权重分布,那为何是上述的计算公式呢?这就涉及到了我们之前为什么说大部分带参机器学习算法只是改变了损失函数,就是因为大部分模型的参数都是通过最优化损失函数(可能还加个规则项)而计算(梯度下降,坐标下降等)得到,这里正是通过最优化指数损失函数从而得到这两个参数的计算公式,具体的推导过程此处不进行展开。
Boosting算法要求基学习器能对特定分布的数据进行学习,即每次都更新样本分布权重,这里书上提到了两种方法:“重赋权法”(re-weighting)和“重采样法”(re-sampling),书上的解释有些晦涩,这里进行展开一下:
重赋权法 : 对每个样本附加一个权重,这时涉及到样本属性与标签的计算,都需要乘上一个权值。重采样法 : 对于一些无法接受带权样本的及学习算法,适合用“重采样法”进行处理。方法大致过程是,根据各个样本的权重,对训练数据进行重采样,初始时样本权重一样,每个样本被采样到的概率一致,每次从N个原始的训练样本中按照权重有放回采样N个样本作为训练集,然后计算训练集错误率,然后调整权重,重复采样,集成多个基学习器。
从偏差-方差分解来看:Boosting算法主要关注于降低偏差,每轮的迭代都关注于训练过程中预测错误的样本,将弱学习提升为强学习器。从AdaBoost的算法流程来看,标准的AdaBoost只适用于二分类问题。在此,当选为数据挖掘十大算法之一的AdaBoost介绍到这里,能够当选正是说明这个算法十分婀娜多姿,背后的数学证明和推导充分证明了这一点,限于篇幅不再继续展开。
