- 15.5 LDA话题模型
15.5 LDA话题模型
话题模型主要用于处理文本类数据,其中隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)是话题模型的杰出代表。在话题模型中,有以下几个基本概念:词(word)、文档(document)、话题(topic)。
词:最基本的离散单元;文档:由一组词组成,词在文档中不计顺序;话题:由一组特定的词组成,这组词具有较强的相关关系。
在现实任务中,一般我们可以得出一个文档的词频分布,但不知道该文档对应着哪些话题,LDA话题模型正是为了解决这个问题。具体来说:LDA认为每篇文档包含多个话题,且其中每一个词都对应着一个话题。因此可以假设文档是通过如下方式生成:

这样一个文档中的所有词都可以认为是通过话题模型来生成的,当已知一个文档的词频分布后(即一个N维向量,N为词库大小),则可以认为:每一个词频元素都对应着一个话题,而话题对应的词频分布则影响着该词频元素的大小。因此很容易写出LDA模型对应的联合概率函数:
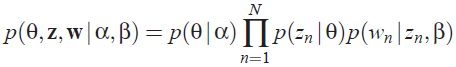
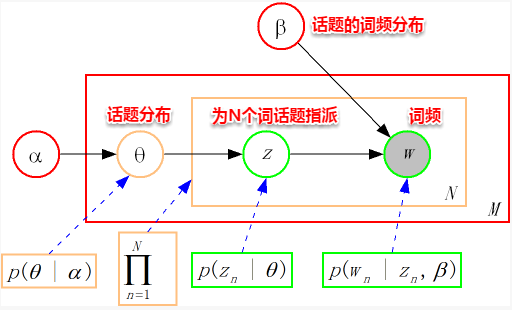
从上图可以看出,LDA的三个表示层被三种颜色表示出来:
corpus-level(红色): α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。document-level(橙色): θ是文档级别的变量,每个文档对应一个θ。word-level(绿色): z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是想从给定的输入语料中学习训练出两个控制参数α和β,当学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量;β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原作者使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。
在此,概率图模型就介绍完毕。上周受到协同训练的启发,让实验的小伙伴做了一个HMM的slides,结果扩充了好多知识,所以完成这篇笔记还是花费了不少功夫,还刚好赶上实验室没空调回到解放前的日子,可谓汗流之作…
