MNIST
在本章当中,我们将会使用 MNIST 这个数据集,它有着 70000 张规格较小的手写数字图片,由美国的高中生和美国人口调查局的职员手写而成。这相当于机器学习当中的“Hello World”,人们无论什么时候提出一个新的分类算法,都想知道该算法在这个数据集上的表现如何。机器学习的初学者迟早也会处理 MNIST 这个数据集。
Scikit-Learn 提供了许多辅助函数,以便于下载流行的数据集。MNIST 是其中一个。下面的代码获取 MNIST
>>> from sklearn.datasets import fetch_mldata>>> mnist = fetch_mldata('MNIST original')>>> mnist{'COL_NAMES': ['label', 'data'],'DESCR': 'mldata.org dataset: mnist-original','data': array([[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]], dtype=uint8),'target': array([ 0., 0., 0., ..., 9., 9., 9.])}
一般而言,由 sklearn 加载的数据集有着相似的字典结构,这包括:
DESCR键描述数据集data键存放一个数组,数组的一行表示一个样例,一列表示一个特征target键存放一个标签数组
让我们看一下这些数组
>>> X, y = mnist["data"], mnist["target"]>>> X.shape(70000, 784)>>> y.shape(70000,)
MNIST 有 70000 张图片,每张图片有 784 个特征。这是因为每个图片都是28*28像素的,并且每个像素的值介于 0~255 之间。让我们看一看数据集的某一个数字。你只需要将某个实例的特征向量,reshape为28*28的数组,然后使用 Matplotlib 的imshow函数展示出来。
%matplotlib inlineimport matplotlibimport matplotlib.pyplot as pltsome_digit = X[36000]some_digit_image = some_digit.reshape(28, 28)plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation="nearest")plt.axis("off")plt.show()
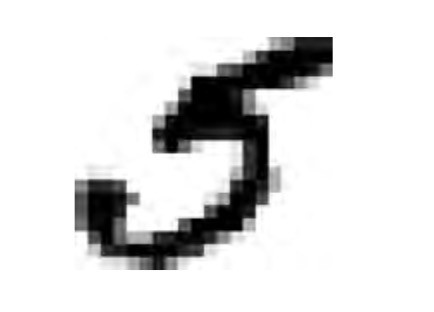
这看起来像个 5,实际上它的标签告诉我们:
>>> y[36000]5.0
图3-1 展示了一些来自 MNIST 数据集的图片。当你处理更加复杂的分类任务的时候,它会让你更有感觉。

先等一下!你总是应该先创建测试集,并且在验证数据之前先把测试集晾到一边。MNIST 数据集已经事先被分成了一个训练集(前 60000 张图片)和一个测试集(最后 10000 张图片)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
让我们打乱训练集。这可以保证交叉验证的每一折都是相似(你不会期待某一折缺少某类数字)。而且,一些学习算法对训练样例的顺序敏感,当它们在一行当中得到许多相似的样例,这些算法将会表现得非常差。打乱数据集将保证这种情况不会发生。
import numpy as npshuffle_index = np.random.permutation(60000)X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
