评价行为:信用分配问题
如果我们知道每一步的最佳动作,我们可以像通常一样训练神经网络,通过最小化估计概率和目标概率之间的交叉熵。这只是通常的监督学习。然而,在强化学习中,智能体获得的指导的唯一途径是通过奖励,奖励通常是稀疏的和延迟的。例如,如果智能体在 100 个步骤内设法平衡杆,它怎么知道它采取的 100 个行动中的哪一个是好的,哪些是坏的?它所知道的是,在最后一次行动之后,杆子坠落了,但最后一次行动肯定不是完全负责的。这被称为信用分配问题:当智能体得到奖励时,很难知道哪些行为应该被信任(或责备)。想想一只狗在行为良好后几小时就会得到奖励,它会明白它得到了什么回报吗?
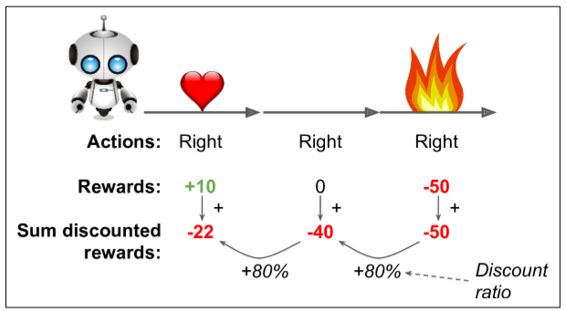
为了解决这个问题,一个通常的策略是基于这个动作后得分的总和来评估这个个动作,通常在每个步骤中应用衰减率r。例如(见图 16-6),如果一个智能体决定连续三次向右,在第一步之后得到 +10 奖励,第二步后得到 0,最后在第三步之后得到 -50,然后假设我们使用衰减率r=0.8,那么第一个动作将得到10 +r×0 + r2×(-50)=-22的分述。如果衰减率接近 0,那么与即时奖励相比,未来的奖励不会有多大意义。相反,如果衰减率接近 1,那么对未来的奖励几乎等于即时回报。典型的衰减率通常为是 0.95 或 0.99。如果衰减率为 0.95,那么未来 13 步的奖励大约是即时奖励的一半(0.9513×0.5),而当衰减率为 0.99,未来 69 步的奖励是即时奖励的一半。在 CartPole 环境下,行为具有相当短期的影响,因此选择 0.95 的折扣率是合理的。
当然,一个好的动作可能会伴随着一些坏的动作,这些动作会导致平衡杆迅速下降,从而导致一个好的动作得到一个低分数(类似的,一个好行动者有时会在一部烂片中扮演主角)。然而,如果我们花足够多的时间来训练游戏,平均下来好的行为会得到比坏的更好的分数。因此,为了获得相当可靠的动作分数,我们必须运行很多次并将所有动作分数归一化(通过减去平均值并除以标准偏差)。之后,我们可以合理地假设消极得分的行为是坏的,而积极得分的行为是好的。现在我们有一个方法来评估每一个动作,我们已经准备好使用策略梯度来训练我们的第一个智能体。让我们看看如何。
