线性模型的正则化
正如我们在第一和第二章看到的那样,降低模型的过拟合的好方法是正则化这个模型(即限制它):模型有越少的自由度,就越难以拟合数据。例如,正则化一个多项式模型,一个简单的方法就是减少多项式的阶数。
对于一个线性模型,正则化的典型实现就是约束模型中参数的权重。 接下来我们将介绍三种不同约束权重的方法:Ridge 回归,Lasso 回归和 Elastic Net。
岭(Ridge)回归
岭回归(也称为 Tikhonov 正则化)是线性回归的正则化版:在损失函数上直接加上一个正则项 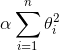 。这使得学习算法不仅能够拟合数据,而且能够使模型的参数权重尽量的小。注意到这个正则项只有在训练过程中才会被加到损失函数。当得到完成训练的模型后,我们应该使用没有正则化的测量方法去评价模型的表现。
。这使得学习算法不仅能够拟合数据,而且能够使模型的参数权重尽量的小。注意到这个正则项只有在训练过程中才会被加到损失函数。当得到完成训练的模型后,我们应该使用没有正则化的测量方法去评价模型的表现。
提示
一般情况下,训练过程使用的损失函数和测试过程使用的评价函数是不一样的。除了正则化,还有一个不同:训练时的损失函数应该在优化过程中易于求导,而在测试过程中,评价函数更应该接近最后的客观表现。一个好的例子:在分类训练中我们使用对数损失(马上我们会讨论它)作为损失函数,但是我们却使用精确率/召回率来作为它的评价函数。
超参数 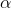 决定了你想正则化这个模型的强度。如果
决定了你想正则化这个模型的强度。如果 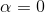 那此时的岭回归便变为了线性回归。如果 非常的大,所有的权重最后都接近于零,最后结果将是一条穿过数据平均值的水平直线。公式 4-8 是岭回归的损失函数:
那此时的岭回归便变为了线性回归。如果 非常的大,所有的权重最后都接近于零,最后结果将是一条穿过数据平均值的水平直线。公式 4-8 是岭回归的损失函数:
公式 4-8:岭回归损失函数
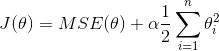
值得注意的是偏差 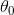 是没有被正则化的(累加运算的开始是
是没有被正则化的(累加运算的开始是 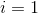 而不是
而不是 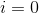 )。如我定义
)。如我定义 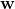 作为特征的权重向量(
作为特征的权重向量(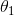 到
到 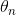 ),那么正则项可以简写成
),那么正则项可以简写成 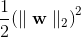 ,其中
,其中 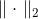 表示权重向量的
表示权重向量的 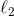 范数。对于梯度下降来说仅仅在均方差梯度向量(公式 4-6)加上一项
范数。对于梯度下降来说仅仅在均方差梯度向量(公式 4-6)加上一项 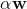 。
。
提示
在使用岭回归前,对数据进行放缩(可以使用
StandardScaler)是非常重要的,算法对于输入特征的数值尺度(scale)非常敏感。大多数的正则化模型都是这样的。
图 4-17 展示了在相同线性数据上使用不同 值的岭回归模型最后的表现。左图中,使用简单的岭回归模型,最后得到了线性的预测。右图中的数据首先使用 10 阶的PolynomialFearures进行扩展,然后使用StandardScaler进行缩放,最后将岭模型应用在处理过后的特征上。这就是带有岭正则项的多项式回归。注意当增大的时候,导致预测曲线变得扁平(即少了极端值,多了一般值),这样减少了模型的方差,却增加了模型的偏差。
对线性回归来说,对于岭回归,我们可以使用封闭方程去计算,也可以使用梯度下降去处理。它们的缺点和优点是一样的。公式 4-9 表示封闭方程的解(矩阵 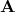 是一个除了左上角有一个
是一个除了左上角有一个 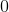 的
的 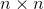 的单位矩,这个 代表偏差项。译者注:偏差 不被正则化的)。
的单位矩,这个 代表偏差项。译者注:偏差 不被正则化的)。
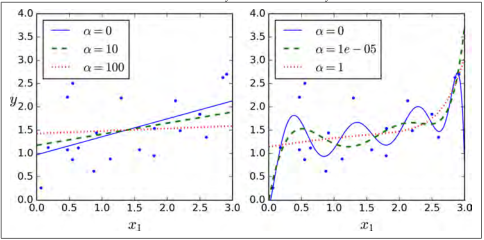
图 4-17:岭回归
公式 4-9:岭回归的封闭方程的解
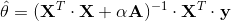
下面是如何使用 Scikit-Learn 来进行封闭方程的求解(使用 Cholesky 法进行矩阵分解对公式 4-9 进行变形):
>>> from sklearn.linear_model import Ridge>>> ridge_reg = Ridge(alpha=1, solver="cholesky")>>> ridge_reg.fit(X, y)>>> ridge_reg.predict([[1.5]])array([[ 1.55071465]]
使用随机梯度法进行求解:
>>> sgd_reg = SGDRegressor(penalty="l2")>>> sgd_reg.fit(X, y.ravel())>>> sgd_reg.predict([[1.5]])array([[ 1.13500145]])
penalty参数指的是正则项的惩罚类型。指定“l2”表明你要在损失函数上添加一项:权重向量 范数平方的一半,这就是简单的岭回归。
Lasso 回归
Lasso 回归(也称 Least Absolute Shrinkage,或者 Selection Operator Regression)是另一种正则化版的线性回归:就像岭回归那样,它也在损失函数上添加了一个正则化项,但是它使用权重向量的 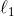 范数而不是权重向量 范数平方的一半。(如公式 4-10)
范数而不是权重向量 范数平方的一半。(如公式 4-10)
公式 4-10:Lasso 回归的损失函数
图 4-18 展示了和图 4-17 相同的事情,仅仅是用 Lasso 模型代替了 Ridge 模型,同时调小了  的值。
的值。
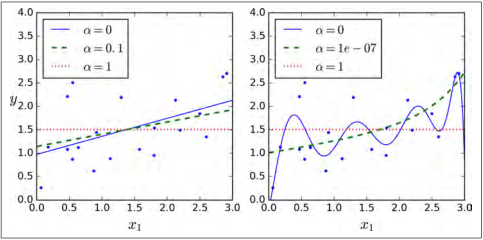
图 4-18:Lasso回归
Lasso 回归的一个重要特征是它倾向于完全消除最不重要的特征的权重(即将它们设置为零)。例如,右图中的虚线所示( ),曲线看起来像一条二次曲线,而且几乎是线性的,这是因为所有的高阶多项特征都被设置为零。换句话说,Lasso回归自动的进行特征选择同时输出一个稀疏模型(即,具有很少的非零权重)。
),曲线看起来像一条二次曲线,而且几乎是线性的,这是因为所有的高阶多项特征都被设置为零。换句话说,Lasso回归自动的进行特征选择同时输出一个稀疏模型(即,具有很少的非零权重)。
你可以从图 4-19 知道为什么会出现这种情况:在左上角图中,后背景的等高线(椭圆)表示了没有正则化的均方差损失函数(),白色的小圆圈表示在当前损失函数上批量梯度下降的路径。前背景的等高线(菱形)表示惩罚,黄色的三角形表示了仅在这个惩罚下批量梯度下降的路径(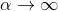 )。注意路径第一次是如何到达
)。注意路径第一次是如何到达 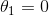 ,然后向下滚动直到它到达
,然后向下滚动直到它到达 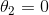 。在右上角图中,等高线表示的是相同损失函数再加上一个
。在右上角图中,等高线表示的是相同损失函数再加上一个 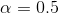 的 惩罚。这幅图中,它的全局最小值在 这根轴上。批量梯度下降首先到达 ,然后向下滚动直到达到全局最小值。 两个底部图显示了相同的情况,只是使用了 惩罚。 规则化的最小值比非规范化的最小值更接近于
的 惩罚。这幅图中,它的全局最小值在 这根轴上。批量梯度下降首先到达 ,然后向下滚动直到达到全局最小值。 两个底部图显示了相同的情况,只是使用了 惩罚。 规则化的最小值比非规范化的最小值更接近于 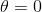 ,但权重不能完全消除。
,但权重不能完全消除。
图 4-19:Ridge 回归和 Lasso 回归对比
提示
在 Lasso 损失函数中,批量梯度下降的路径趋向与在低谷有一个反弹。这是因为在
Lasso 损失函数在  处无法进行微分运算,但是梯度下降如果你使用子梯度向量
处无法进行微分运算,但是梯度下降如果你使用子梯度向量  后它可以在任何
后它可以在任何 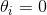 的情况下进行计算。公式 4-11 是在 Lasso 损失函数上进行梯度下降的子梯度向量公式。
的情况下进行计算。公式 4-11 是在 Lasso 损失函数上进行梯度下降的子梯度向量公式。
公式 4-11:Lasso 回归子梯度向量
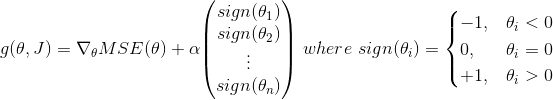
下面是一个使用 Scikit-Learn 的Lasso类的小例子。你也可以使用SGDRegressor(penalty="l1")来代替它。
>>> from sklearn.linear_model import Lasso>>> lasso_reg = Lasso(alpha=0.1)>>> lasso_reg.fit(X, y)>>> lasso_reg.predict([[1.5]])array([ 1.53788174]
弹性网络(ElasticNet)
弹性网络介于 Ridge 回归和 Lasso 回归之间。它的正则项是 Ridge 回归和 Lasso 回归正则项的简单混合,同时你可以控制它们的混合率  ,当
,当 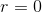 时,弹性网络就是 Ridge 回归,当
时,弹性网络就是 Ridge 回归,当 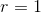 时,其就是 Lasso 回归。具体表示如公式 4-12。
时,其就是 Lasso 回归。具体表示如公式 4-12。
公式 4-12:弹性网络损失函数
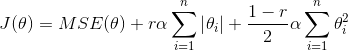
那么我们该如何选择线性回归,岭回归,Lasso 回归,弹性网络呢?一般来说有一点正则项的表现更好,因此通常你应该避免使用简单的线性回归。岭回归是一个很好的首选项,但是如果你的特征仅有少数是真正有用的,你应该选择 Lasso 和弹性网络。就像我们讨论的那样,它两能够将无用特征的权重降为零。一般来说,弹性网络的表现要比 Lasso 好,因为当特征数量比样本的数量大的时候,或者特征之间有很强的相关性时,Lasso 可能会表现的不规律。下面是一个使用 Scikit-Learn ElasticNet(l1_ratio指的就是混合率 )的简单样本:
>>> from sklearn.linear_model import ElasticNet>>> elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)>>> elastic_net.fit(X, y)>>> elastic_net.predict([[1.5]])array([ 1.54333232])
早期停止法(Early Stopping)
对于迭代学习算法,有一种非常特殊的正则化方法,就像梯度下降在验证错误达到最小值时立即停止训练那样。我们称为早期停止法。图 4-20 表示使用批量梯度下降来训练一个非常复杂的模型(一个高阶多项式回归模型)。随着训练的进行,算法一直学习,它在训练集上的预测误差(RMSE)自然而然的下降。然而一段时间后,验证误差停止下降,并开始上升。这意味着模型在训练集上开始出现过拟合。一旦验证错误达到最小值,便提早停止训练。这种简单有效的正则化方法被 Geoffrey Hinton 称为“完美的免费午餐”
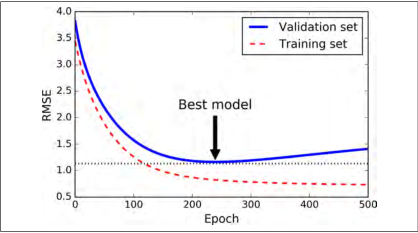
图 4-20:早期停止法
提示
随机梯度和小批量梯度下降不是平滑曲线,你可能很难知道它是否达到最小值。 一种解决方案是,只有在验证误差高于最小值一段时间后(你确信该模型不会变得更好了),才停止,之后将模型参数回滚到验证误差最小值。
下面是一个早期停止法的基础应用:
from sklearn.base import clonesgd_reg = SGDRegressor(n_iter=1, warm_start=True, penalty=None,learning_rate="constant", eta0=0.0005)minimum_val_error = float("inf")best_epoch = Nonebest_model = Nonefor epoch in range(1000):sgd_reg.fit(X_train_poly_scaled, y_train)y_val_predict = sgd_reg.predict(X_val_poly_scaled)val_error = mean_squared_error(y_val_predict, y_val)if val_error < minimum_val_error:minimum_val_error = val_errorbest_epoch = epochbest_model = clone(sgd_reg)
注意:当warm_start=True时,调用fit()方法后,训练会从停下来的地方继续,而不是从头重新开始。
