时间差分学习与 Q 学习
具有离散动作的强化学习问题通常可以被建模为马尔可夫决策过程,但是智能体最初不知道转移概率是什么(它不知道T),并且它不知道奖励会是什么(它不知道R)。它必须经历每一个状态和每一次转变并且至少知道一次奖励,并且如果要对转移概率进行合理的估计,就必须经历多次。
时间差分学习(TD 学习)算法与数值迭代算法非常类似,但考虑到智能体仅具有 MDP 的部分知识。一般来说,我们假设智能体最初只知道可能的状态和动作,没有更多了。智能体使用探索策略,例如,纯粹的随机策略来探索 MDP,并且随着它的发展,TD 学习算法基于实际观察到的转换和奖励来更新状态值的估计(见公式 16-4)。
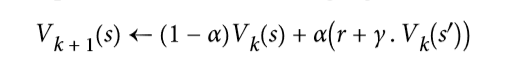
其中:
a是学习率(例如 0.01)
TD 学习与随机梯度下降有许多相似之处,特别是它一次处理一个样本的行为。就像 SGD 一样,只有当你逐渐降低学习速率时,它才能真正收敛(否则它将在极值点震荡)。
对于每个状态S,该算法只跟踪智能体离开该状态时立即获得的奖励的平均值,再加上它期望稍后得到的奖励(假设它的行为最佳)。
类似地,此时的Q 学习算法是 Q 值迭代算法的改编版本,其适应转移概率和回报在初始未知的情况(见公式16-5)。
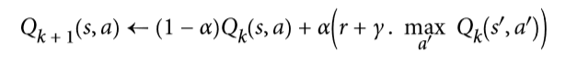
对于每一个状态动作对(s,a),该算法跟踪智能体在以动作A离开状态S时获得的即时奖励平均值R,加上它期望稍后得到的奖励。由于目标策略将最优地运行,所以我们取下一状态的 Q 值估计的最大值。
以下是如何实现 Q 学习:
import numpy.random as rndlearning_rate0 = 0.05learning_rate_decay = 0.1n_iterations = 20000s = 0 # 在状态 0开始Q = np.full((3, 3), -np.inf) # -inf 对应着不可能的动作for state, actions in enumerate(possible_actions):Q[state, actions] = 0.0 # 对于所有可能的动作初始化为 0.0for iteration in range(n_iterations):a = rnd.choice(possible_actions[s]) # 随机选择动作sp = rnd.choice(range(3), p=T[s, a]) # 使用 T[s, a] 挑选下一状态reward = R[s, a, sp]learning_rate = learning_rate0 / (1 + iteration * learning_rate_decay)Q[s, a] = learning_rate * Q[s, a] + (1 - learning_rate) * (reward + discount_rate * np.max(Q[sp]))s = sp # 移动至下一状态
给定足够的迭代,该算法将收敛到最优 Q 值。这被称为离线策略算法,因为正在训练的策略不是正在执行的策略。令人惊讶的是,该算法能够通过观察智能体行为随机学习(例如学习当你的老师是一个醉猴子时打高尔夫球)最佳策略。我们能做得更好吗?
