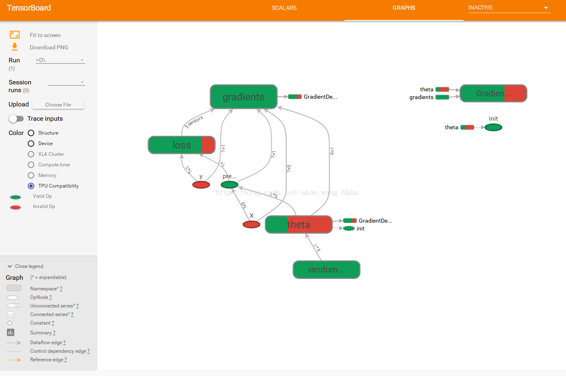
名称作用域
当处理更复杂的模型(如神经网络)时,该图可以很容易地与数千个节点混淆。 为了避免这种情况,您可以创建名称作用域来对相关节点进行分组。 例如,我们修改以前的代码来定义名为loss的名称作用域内的错误和mse操作:
with tf.name_scope("loss") as scope:error = y_pred - ymse = tf.reduce_mean(tf.square(error), name="mse")
在作用域内定义的每个op的名称现在以loss/为前缀:
>>> print(error.op.name)loss/sub>>> print(mse.op.name)loss/mse
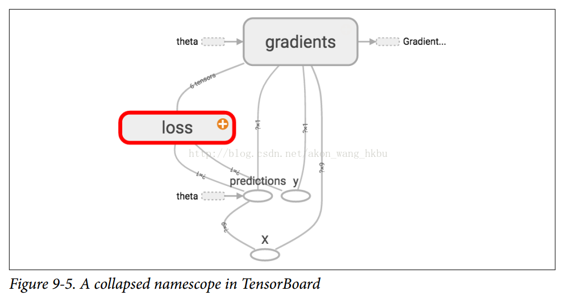
在 TensorBoard 中,mse和error节点现在出现在loss命名空间中,默认情况下会出现崩溃(图 9-5)。
完整代码
import numpy as npfrom sklearn.datasets import fetch_california_housingimport tensorflow as tffrom sklearn.preprocessing import StandardScalerhousing = fetch_california_housing()m, n = housing.data.shapeprint("数据集:{}行,{}列".format(m,n))housing_data_plus_bias = np.c_[np.ones((m, 1)), housing.data]scaler = StandardScaler()scaled_housing_data = scaler.fit_transform(housing.data)scaled_housing_data_plus_bias = np.c_[np.ones((m, 1)), scaled_housing_data]from datetime import datetimenow = datetime.utcnow().strftime("%Y%m%d%H%M%S")root_logdir = r"D://tf_logs"logdir = "{}/run-{}/".format(root_logdir, now)n_epochs = 1000learning_rate = 0.01X = tf.placeholder(tf.float32, shape=(None, n + 1), name="X")y = tf.placeholder(tf.float32, shape=(None, 1), name="y")theta = tf.Variable(tf.random_uniform([n + 1, 1], -1.0, 1.0, seed=42), name="theta")y_pred = tf.matmul(X, theta, name="predictions")def fetch_batch(epoch, batch_index, batch_size):np.random.seed(epoch * n_batches + batch_index) # not shown in the bookindices = np.random.randint(m, size=batch_size) # not shownX_batch = scaled_housing_data_plus_bias[indices] # not showny_batch = housing.target.reshape(-1, 1)[indices] # not shownreturn X_batch, y_batchwith tf.name_scope("loss") as scope:error = y_pred - ymse = tf.reduce_mean(tf.square(error), name="mse")optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)training_op = optimizer.minimize(mse)init = tf.global_variables_initializer()mse_summary = tf.summary.scalar('MSE', mse)file_writer = tf.summary.FileWriter(logdir, tf.get_default_graph())n_epochs = 10batch_size = 100n_batches = int(np.ceil(m / batch_size))with tf.Session() as sess:sess.run(init)for epoch in range(n_epochs):for batch_index in range(n_batches):X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)if batch_index % 10 == 0:summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})step = epoch * n_batches + batch_indexfile_writer.add_summary(summary_str, step)sess.run(training_op, feed_dict={X: X_batch, y: y_batch})best_theta = theta.eval()file_writer.flush()file_writer.close()print("Best theta:")print(best_theta)