神经网络策略
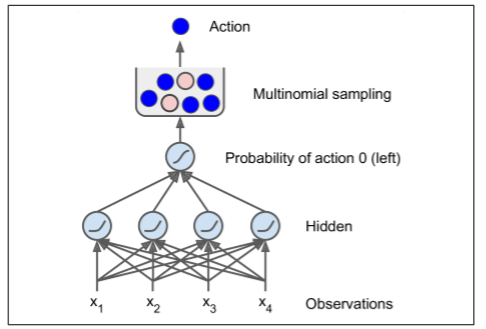
让我们创建一个神经网络策略。就像之前我们编码的策略一样,这个神经网络将把观察作为输入,输出要执行的动作。更确切地说,它将估计每个动作的概率,然后我们将根据估计的概率随机地选择一个动作(见图 16-5)。在 CartPole 环境中,只有两种可能的动作(左或右),所以我们只需要一个输出神经元。它将输出动作 0(左)的概率p,动作 1(右)的概率显然将是1 - p。
例如,如果它输出 0.7,那么我们将以 70% 的概率选择动作 0,以 30% 的概率选择动作 1。
你可能奇怪为什么我们根据神经网络给出的概率来选择随机的动作,而不是选择最高分数的动作。这种方法使智能体在探索新的行为和利用那些已知可行的行动之间找到正确的平衡。举个例子:假设你第一次去餐馆,所有的菜看起来同样吸引人,所以你随机挑选一个。如果菜好吃,你可以增加下一次点它的概率,但是你不应该把这个概率提高到 100%,否则你将永远不会尝试其他菜肴,其中一些甚至比你尝试的更好。
还要注意,在这个特定的环境中,过去的动作和观察可以被安全地忽略,因为每个观察都包含环境的完整状态。如果有一些隐藏状态,那么你也需要考虑过去的行为和观察。例如,如果环境仅仅揭示了推车的位置,而不是它的速度,那么你不仅要考虑当前的观测,还要考虑先前的观测,以便估计当前的速度。另一个例子是当观测是有噪声的的,在这种情况下,通常你想用过去的观察来估计最可能的当前状态。因此,CartPole 问题是简单的;观测是无噪声的,而且它们包含环境的全状态。
import tensorflow as tffrom tensorflow.contrib.layers import fully_connected# 1. 声明神经网络结构n_inputs = 4 # == env.observation_space.shape[0]n_hidden = 4 # 这只是个简单的测试,不需要过多的隐藏层n_outputs = 1 # 只输出向左加速的概率initializer = tf.contrib.layers.variance_scaling_initializer()# 2. 建立神经网络X = tf.placeholder(tf.float32, shape=[None, n_inputs]) hidden = fully_connected(X, n_hidden, activation_fn=tf.nn.elu,weights_initializer=initializer) # 隐层激活函数使用指数线性函数logits = fully_connected(hidden, n_outputs, activation_fn=None,weights_initializer=initializer)outputs = tf.nn.sigmoid(logits)# 3. 在概率基础上随机选择动作p_left_and_right = tf.concat(axis=1, values=[outputs, 1 - outputs])action = tf.multinomial(tf.log(p_left_and_right), num_samples=1)init = tf.global_variables_initializer()
让我们通读代码:
在导入之后,我们定义了神经网络体系结构。输入的数量是观测空间的大小(在 CartPole 的情况下是 4 个),我们只有 4 个隐藏单元,并且不需要更多,并且我们只有 1 个输出概率(向左的概率)。
接下来我们构建了神经网络。在这个例子中,它是一个 vanilla 多层感知器,只有一个输出。注意,输出层使用 Logistic(Sigmoid)激活函数,以便输出从 0 到 1 的概率。如果有两个以上的可能动作,每个动作都会有一个输出神经元,相应的你将使用 Softmax 激活函数。
最后,我们调用
multinomial()函数来选择一个随机动作。该函数独立地采样一个(或多个)整数,给定每个整数的对数概率。例如,如果通过设置num_samples=5,令数组为[np.log(0.5), np.log(0.2), np.log(0.3)]来调用它,那么它将输出五个整数,每个整数都有 50% 的概率是 0,20% 为 1,30% 为 2。在我们的情况下,我们只需要一个整数来表示要采取的行动。由于输出张量(output)仅包含向左的概率,所以我们必须首先将 1 - output 连接它,以得到包含左和右动作的概率的张量。请注意,如果有两个以上的可能动作,神经网络将不得不输出每个动作的概率,这时你就不需要连接步骤了。
好了,现在我们有一个可以观察和输出动作的神经网络了,那我们怎么训练它呢?
