线性回归
在第一章,我们介绍了一个简单的生活满意度回归模型:
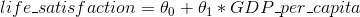
这个模型仅仅是输入量GDP_per_capita的线性函数,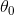 和
和 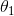 是这个模型的参数,线性模型更一般化的描述指通过计算输入变量的加权和,并加上一个常数偏置项(截距项)来得到一个预测值。如公式 4-1:
是这个模型的参数,线性模型更一般化的描述指通过计算输入变量的加权和,并加上一个常数偏置项(截距项)来得到一个预测值。如公式 4-1:
公式 4-1:线性回归预测模型
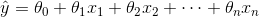
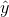 表示预测结果
表示预测结果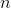 表示特征的个数
表示特征的个数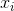 表示第
表示第i个特征的值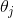 表示第
表示第j个参数(包括偏置项 和特征权重值 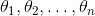 )
)
上述公式可以写成更为简洁的向量形式,如公式 4-2:
公式 4-2:线性回归预测模型(向量形式)
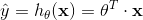
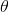 表示模型的参数向量包括偏置项 和特征权重值 到
表示模型的参数向量包括偏置项 和特征权重值 到 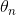
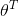 表示向量的转置(行向量变为了列向量)
表示向量的转置(行向量变为了列向量)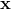 为每个样本中特征值的向量形式,包括
为每个样本中特征值的向量形式,包括 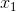 到
到 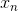 ,而且
,而且 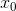 恒为 1
恒为 1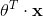 表示 和
表示 和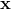 的点积
的点积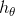 表示参数为 的假设函数
表示参数为 的假设函数
怎么样去训练一个线性回归模型呢?好吧,回想一下,训练一个模型指的是设置模型的参数使得这个模型在训练集的表现较好。为此,我们首先需要找到一个衡量模型好坏的评定方法。在第二章,我们介绍到在回归模型上,最常见的评定标准是均方根误差(RMSE,详见公式 2-1)。因此,为了训练一个线性回归模型,你需要找到一个 值,它使得均方根误差(标准误差)达到最小值。实践过程中,最小化均方误差比最小化均方根误差更加的简单,这两个过程会得到相同的 ,因为函数在最小值时候的自变量,同样能使函数的方根运算得到最小值。
在训练集 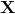 上使用公式 4-3 来计算线性回归假设 的均方差(
上使用公式 4-3 来计算线性回归假设 的均方差( )。
)。
公式 4-3:线性回归模型的 MSE 损失函数
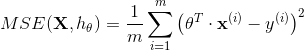
公式中符号的含义大多数都在第二章(详见“符号”)进行了说明,不同的是:为了突出模型的参数向量 ,使用 来代替 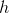 。以后的使用中为了公式的简洁,使用
。以后的使用中为了公式的简洁,使用 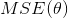 来代替
来代替 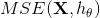 。
。
正态方程
为了找到最小化损失函数的 值,可以采用公式解,换句话说,就是可以通过解正态方程直接得到最后的结果。
公式 4-4:正态方程
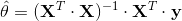
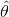 指最小化损失 的值
指最小化损失 的值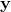 是一个向量,其包含了
是一个向量,其包含了 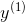 到
到 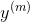 的值
的值
让我们生成一些近似线性的数据(如图 4-1)来测试一下这个方程。
import numpy as npX = 2 * np.random.rand(100, 1)y = 4 + 3 * X + np.random.randn(100, 1)
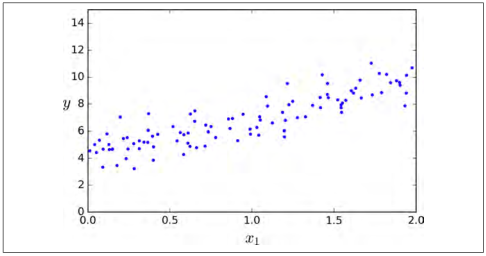
图 4-1:随机线性数据集
现在让我们使用正态方程来计算 ,我们将使用 Numpy 的线性代数模块(np.linalg)中的inv()函数来计算矩阵的逆,以及dot()方法来计算矩阵的乘法。
X_b = np.c_[np.ones((100, 1)), X]theta_best = np.linalg.inv(X_b.T.dot(X_B)).dot(X_b.T).dot(y)
我们生产数据的函数实际上是 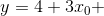 。让我们看一下最后的计算结果。
。让我们看一下最后的计算结果。
>>> theta_bestarray([[4.21509616],[2.77011339]])
我们希望最后得到的参数为 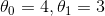 而不是
而不是 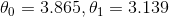 (译者注:我认为应该是
(译者注:我认为应该是 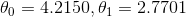 )。这已经足够了,由于存在噪声,参数不可能达到到原始函数的值。
)。这已经足够了,由于存在噪声,参数不可能达到到原始函数的值。
现在我们能够使用 来进行预测:
>>> X_new = np.array([[0],[2]])>>> X_new_b = np.c_[np.ones((2, 1)), X_new]>>> y_predict = X_new_b.dot(theta.best)>>> y_predictarray([[4.21509616],[9.75532293]])
画出这个模型的图像,如图 4-2
plt.plot(X_new,y_predict,"r-")plt.plot(X,y,"b.")plt.axis([0,2,0,15])plt.show()
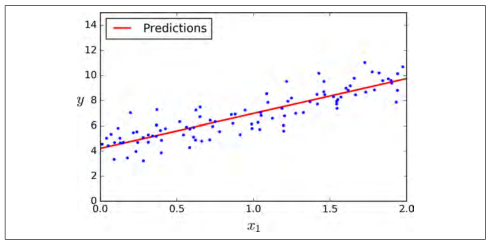
图4-2:线性回归预测
使用下面的 Scikit-Learn 代码可以达到相同的效果:
>>> from sklearn.linear_model import LinearRegression>>> lin_reg = LinearRegression()>>> lin_reg.fit(X,y)>>> lin_reg.intercept_, lin_reg.coef_(array([4.21509616]),array([2.77011339]))>>> lin_reg.predict(X_new)array([[4.21509616],[9.75532293]])
计算复杂度
正态方程需要计算矩阵 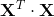 的逆,它是一个
的逆,它是一个 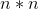 的矩阵( 是特征的个数)。这样一个矩阵求逆的运算复杂度大约在
的矩阵( 是特征的个数)。这样一个矩阵求逆的运算复杂度大约在 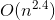 到
到 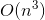 之间,具体值取决于计算方式。换句话说,如果你将你的特征个数翻倍的话,其计算时间大概会变为原来的 5.3(
之间,具体值取决于计算方式。换句话说,如果你将你的特征个数翻倍的话,其计算时间大概会变为原来的 5.3(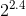 )到 8(
)到 8(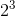 )倍。
)倍。
提示
当特征的个数较大的时候(例如:特征数量为 100000),正态方程求解将会非常慢。
有利的一面是,这个方程在训练集上对于每一个实例来说是线性的,其复杂度为 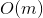 ,因此只要有能放得下它的内存空间,它就可以对大规模数据进行训练。同时,一旦你得到了线性回归模型(通过解正态方程或者其他的算法),进行预测是非常快的。因为模型中计算复杂度对于要进行预测的实例数量和特征个数都是线性的。 换句话说,当实例个数变为原来的两倍多的时候(或特征个数变为原来的两倍多),预测时间也仅仅是原来的两倍多。
,因此只要有能放得下它的内存空间,它就可以对大规模数据进行训练。同时,一旦你得到了线性回归模型(通过解正态方程或者其他的算法),进行预测是非常快的。因为模型中计算复杂度对于要进行预测的实例数量和特征个数都是线性的。 换句话说,当实例个数变为原来的两倍多的时候(或特征个数变为原来的两倍多),预测时间也仅仅是原来的两倍多。
接下来,我们将介绍另一种方法去训练模型。这种方法适合在特征个数非常多,训练实例非常多,内存无法满足要求的时候使用。
