CNN 架构
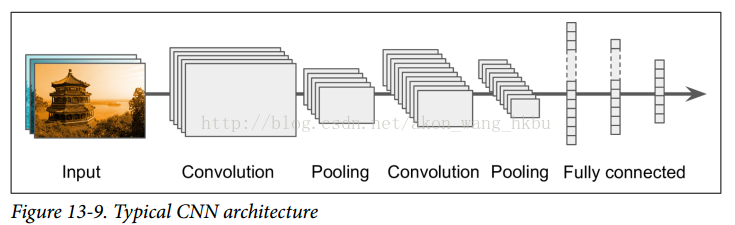
典型的 CNN 体系结构有一些卷积层(每一个通常跟着一个 ReLU 层),然后是一个池化层,然后是另外几个卷积层(+ ReLU),然后是另一个池化层,等等。 随着网络的进展,图像变得越来越小,但是由于卷积层的缘故,图像通常也会越来越深(即更多的特征映射)(见图 13-9)。 在堆栈的顶部,添加由几个全连接层(+ ReLU)组成的常规前馈神经网络,并且最终层输出预测(例如,输出估计类别概率的 softmax 层)。
一个常见的错误是使用太大的卷积核。 通常可以通过将两个3×3内核堆叠在一起来获得与9×9内核相同的效果,计算量更少。
多年来,这种基础架构的变体已经被开发出来,导致了该领域的惊人进步。 这种进步的一个很好的衡量标准是比赛中的错误率,比如 ILSVRC ImageNet 的挑战。 在这个比赛中,图像分类的五大误差率在五年内从 26% 下降到仅仅 3% 左右。 前五位错误率是系统前5位预测未包含正确答案的测试图像的数量。 图像很大(256 像素),有 1000 个类,其中一些非常微妙(尝试区分 120 个狗的品种)。 查看获奖作品的演变是了解 CNN 如何工作的好方法。
我们先来看看经典的 LeNet-5 架构(1998 年),然后是 ILSVRC 挑战赛的三名获胜者 AlexNet(2012),GoogLeNet(2014)和 ResNet(2015)。
其他视觉任务在其他视觉任务中,如物体检测和定位以及图像分割,也取得了惊人的进展。 在物体检测和定位中,神经网络通常输出图像中各种物体周围的一系列边界框。 例如,参 见Maxine Oquab 等人的 2015 年论文,该论文为每个客体类别输出热图,或者 Russell Stewart 等人的 2015 年论文,该论文结合使用 CNN 来检测人脸,并使用递归神经网络来输出 围绕它们的一系列边界框。 在图像分割中,网络输出图像(通常与输入大小相同),其中每个像素指示相应输入像素所属的对象的类别。 例如,查看 Evan Shelhamer 等人的 2016 年论文。
