多个服务器的多个设备
要跨多台服务器运行图形,首先需要定义一个集群。 一个集群由一个或多个 TensorFlow 服务器组成,称为任务,通常分布在多台机器上(见图 12-6)。 每项任务都属于一项作业。 作业只是一组通常具有共同作用的任务,例如跟踪模型参数(例如,参数服务器通常命名为"ps",parameter server)或执行计算(这样的作业通常被命名为"worker")。
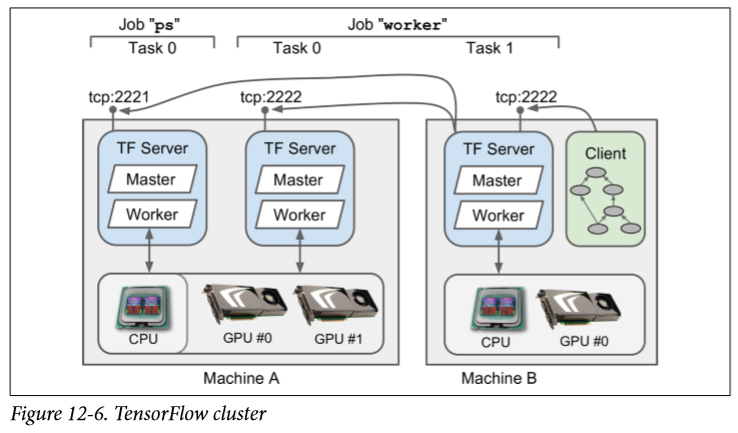
以下集群规范定义了两个作业"ps"和"worker",分别包含一个任务和两个任务。 在这个例子中,机器A托管着两个 TensorFlow 服务器(即任务),监听不同的端口:一个是"ps"作业的一部分,另一个是"worker"作业的一部分。 机器B仅托管一台 TensorFlow 服务器,这是"worker"作业的一部分。
cluster_spec = tf.train.ClusterSpec({"ps": ["machine-a.example.com:2221", # /job:ps/task:0],"worker": ["machine-a.example.com:2222", # /job:worker/task:0"machine-b.example.com:2222", # /job:worker/task:1]})
要启动 TensorFlow 服务器,您必须创建一个服务器对象,并向其传递集群规范(以便它可以与其他服务器通信)以及它自己的作业名称和任务编号。 例如,要启动第一个辅助任务,您需要在机器 A 上运行以下代码:
server = tf.train.Server(cluster_spec, job_name="worker", task_index=0)
每台机器只运行一个任务通常比较简单,但前面的例子表明 TensorFlow 允许您在同一台机器上运行多个任务(如果需要的话)。 如果您在一台机器上安装了多台服务器,则需要确保它们不会全部尝试抓取每个 GPU 的所有 RAM,如前所述。 例如,在图12-6中,"ps"任务没有看到 GPU 设备,想必其进程是使用CUDA_VISIBLE_DEVICES =""启动的。 请注意,CPU由位于同一台计算机上的所有任务共享。
如果您希望进程除了运行 TensorFlow 服务器之外什么都不做,您可以通过告诉它等待服务器使用join()方法来完成,从而阻塞主线程(否则服务器将在您的主线程退出)。 由于目前没有办法阻止服务器,这实际上会永远阻止:
server.join() # blocks until the server stops (i.e., never)
