- 十二、设备和服务器上的分布式 TensorFlow
十二、设备和服务器上的分布式 TensorFlow
在第 11 章,我们讨论了几种可以明显加速训练的技术:更好的权重初始化,批量标准化,复杂的优化器等等。 但是,即使采用了所有这些技术,在具有单个 CPU 的单台机器上训练大型神经网络可能需要几天甚至几周的时间。
在本章中,我们将看到如何使用 TensorFlow 在多个设备(CPU 和 GPU)上分配计算并将它们并行运行(参见图 12-1)。 首先,我们会先在一台机器上的多个设备上分配计算,然后在多台机器上的多个设备上分配计算。
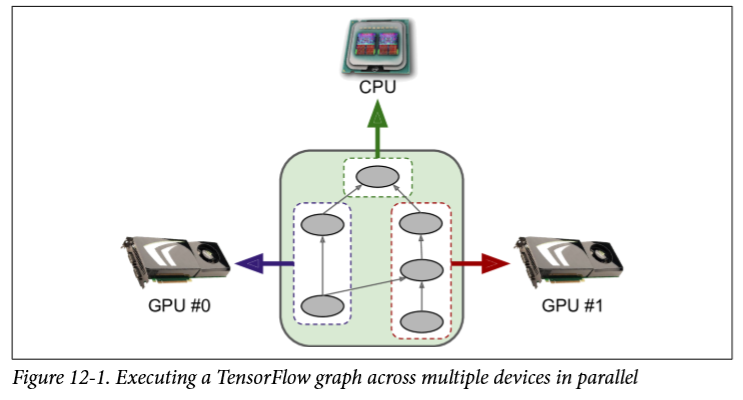
与其他神经网络框架相比,TensorFlow 对分布式计算的支持是其主要亮点之一。 它使您可以完全控制如何跨设备和服务器分布(或复制)您的计算图,并且可以让您以灵活的方式并行和同步操作,以便您可以在各种并行方法之间进行选择。
我们来看一些最流行的方法来并行执行和训练一个神经网络,这让我们不再需要等待数周才能完成训练算法,而最终可能只会等待几个小时。 这不仅可以节省大量时间,还意味着您可以更轻松地尝试各种模型,并经常重新训练模型上的新数据。
还有其他很好的并行化例子,包括当我们在微调模型时可以探索更大的超参数空间,并有效地运行大规模神经网络。
但我们必须先学会走路才能跑步。 我们先从一台机器上的几个 GPU 上并行化简单图形开始。
