管理 GPU 内存
默认情况下,TensorFlow 会在您第一次运行图形时自动获取所有可用 GPU 中的所有 RAM,因此当第一个程序仍在运行时,您将无法启动第二个 TensorFlow 程序。 如果你尝试,你会得到以下错误:
E [...]/cuda_driver.cc:965] failed to allocate 3.66G (3928915968 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
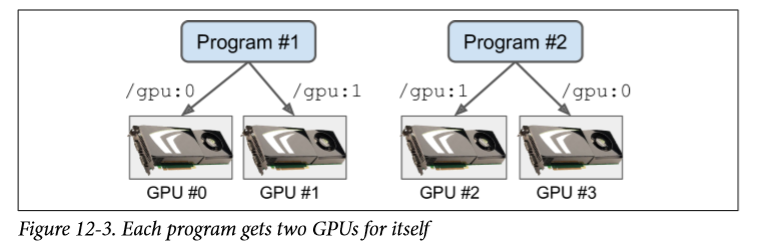
一种解决方案是在不同的 GPU 卡上运行每个进程。 为此,最简单的选择是设置CUDA_VISIBLE_DEVICES环境变量,以便每个进程只能看到对应的 GPU 卡。 例如,你可以像这样启动两个程序:
$ CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py# and in another terminal:$ CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py
程序 # 1 只会看到 GPU 卡 0 和 1(分别编号为 0 和 1),程序 # 2 只会看到 GPU 卡 2 和 3(分别编号为 1 和 0)。 一切都会正常工作(见图 12-3)。
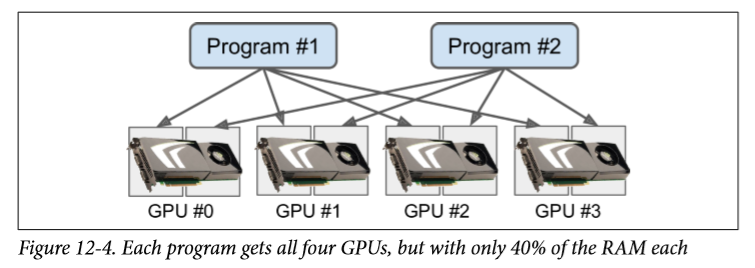
另一种选择是告诉 TensorFlow 只抓取一小部分内存。 例如,要使 TensorFlow 只占用每个 GPU 内存的 40%,您必须创建一个ConfigProto对象,将其gpu_options.per_process_gpu_memory_fraction选项设置为 0.4,并使用以下配置创建session:
config = tf.ConfigProto()config.gpu_options.per_process_gpu_memory_fraction = 0.4session = tf.Session(config=config)
现在像这样的两个程序可以使用相同的 GPU 卡并行运行(但不是三个,因为3×0.4> 1)。 见图 12-4。
如果在两个程序都运行时运行nvidia-smi命令,则应该看到每个进程占用每个卡的总 RAM 大约 40%:

另一种选择是告诉 TensorFlow 只在需要时才抓取内存。 为此,您必须将config.gpu_options.allow_growth设置为True。但是,TensorFlow 一旦抓取内存就不会释放内存(以避免内存碎片),因此您可能会在一段时间后内存不足。 是否使用此选项可能难以确定,因此一般而言,您可能想要坚持之前的某个选项。
好的,现在你已经有了一个支持 GPU 的 TensorFlow 安装。 让我们看看如何使用它!
