梯度消失/爆炸问题
正如我们在第 10 章中所讨论的那样,反向传播算法的工作原理是从输出层到输入层,传播误差的梯度。 一旦该算法已经计算了网络中每个参数的损失函数的梯度,它就使用这些梯度来用梯度下降步骤来更新每个参数。
不幸的是,梯度往往变得越来越小,随着算法进展到较低层。 结果,梯度下降更新使得低层连接权重实际上保持不变,并且训练永远不会收敛到良好的解决方案。 这被称为梯度消失问题。 在某些情况下,可能会发生相反的情况:梯度可能变得越来越大,许多层得到了非常大的权重更新,算法发散。这是梯度爆炸的问题,在循环神经网络中最为常见(见第 14 章)。 更一般地说,深度神经网络受梯度不稳定之苦; 不同的层次可能以非常不同的速度学习。
虽然这种不幸的行为已经经过了相当长的一段时间的实验观察(这是造成深度神经网络大部分时间都被抛弃的原因之一),但直到 2010 年左右,人们才有了明显的进步。 Xavier Glorot 和 Yoshua Bengio 发表的题为《Understanding the Difficulty of Training Deep Feedforward Neural Networks》的论文发现了一些疑问,包括流行的 sigmoid 激活函数和当时最受欢迎的权重初始化技术的组合,即随机初始化时使用平均值为 0,标准差为 1 的正态分布。简而言之,他们表明,用这个激活函数和这个初始化方案,每层输出的方差远大于其输入的方差。网络正向,每层的方差持续增加,直到激活函数在顶层饱和。这实际上是因为logistic函数的平均值为 0.5 而不是 0(双曲正切函数的平均值为 0,表现略好于深层网络中的logistic函数)
看一下logistic 激活函数(参见图 11-1),可以看到当输入变大(负或正)时,函数饱和在 0 或 1,导数非常接近 0。因此,当反向传播开始时, 它几乎没有梯度通过网络传播回来,而且由于反向传播通过顶层向下传递,所以存在的小梯度不断地被稀释,因此较低层确实没有任何东西可用。
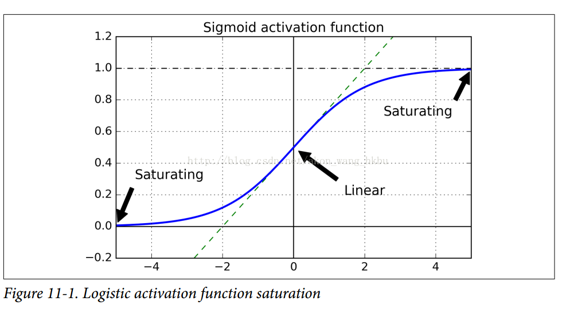
Glorot 和 Bengio 在他们的论文中提出了一种显著缓解这个问题的方法。 我们需要信号在两个方向上正确地流动:在进行预测时是正向的,在反向传播梯度时是反向的。 我们不希望信号消失,也不希望它爆炸并饱和。 为了使信号正确流动,作者认为,我们需要每层输出的方差等于其输入的方差。(这里有一个比喻:如果将麦克风放大器的旋钮设置得太接近于零,人们听不到声音,但是如果将麦克风放大器设置得太大,声音就会饱和,人们就会听不懂你在说什么。 现在想象一下这样一个放大器的链条:它们都需要正确设置,以便在链条的末端响亮而清晰地发出声音。 你的声音必须以每个放大器的振幅相同的幅度出来。)而且我们也需要梯度在相反方向上流过一层之前和之后有相同的方差(如果您对数学细节感兴趣,请查阅论文)。实际上不可能保证两者都是一样的,除非这个层具有相同数量的输入和输出连接,但是他们提出了一个很好的折衷办法,在实践中证明这个折中办法非常好:随机初始化连接权重必须如公式 11-1 所描述的那样。其中n_inputs和n_outputs是权重正在被初始化的层(也称为扇入和扇出)的输入和输出连接的数量。 这种初始化策略通常被称为Xavier初始化(在作者的名字之后),或者有时是 Glorot 初始化。

当输入连接的数量大致等于输出连接的数量时,可以得到更简单的等式 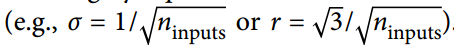 我们在第 10 章中使用了这个简化的策略。
我们在第 10 章中使用了这个简化的策略。
使用 Xavier 初始化策略可以大大加快训练速度,这是导致深度学习目前取得成功的技巧之一。 最近的一些论文针对不同的激活函数提供了类似的策略,如表 11-1 所示。 ReLU 激活函数(及其变体,包括简称 ELU 激活)的初始化策略有时称为 He 初始化(在其作者的姓氏之后)。

默认情况下,fully_connected()函数(在第 10 章中介绍)使用 Xavier 初始化(具有统一的分布)。 你可以通过使用如下所示的variance_scaling_initializer()函数来将其更改为 He 初始化:
注意:本书使用tensorflow.contrib.layers.fully_connected()而不是tf.layers.dense()(本章编写时不存在)。 现在最好使用tf.layers.dense(),因为contrib模块中的任何内容可能会更改或删除,恕不另行通知。 dense()函数几乎与fully_connected()函数完全相同。 与本章有关的主要差异是:
几个参数被重新命名:范围变成名字,activation_fn变成激活(类似地,_fn后缀从诸如normalizer_fn之类的其他参数中移除),weights_initializer变成kernel_initializer等等。默认激活现在是None,而不是tf.nn.relu。 它不支持tensorflow.contrib.framework.arg_scope()(稍后在第 11 章中介绍)。 它不支持正则化的参数(稍后在第 11 章介绍)。
he_init = tf.contrib.layers.variance_scaling_initializer()hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,kernel_initializer=he_init, name="hidden1")
He 初始化只考虑了扇入,而不是像 Xavier 初始化那样扇入和扇出之间的平均值。 这也是variance_scaling_initializer()函数的默认值,但您可以通过设置参数mode ="FAN_AVG"来更改它。
