无监督预训练使用栈式自编码器
正如我们在第 11 章中讨论的那样,如果您正在处理复杂的监督任务,但您没有大量标记的训练数据,则一种解决方案是找到执行类似任务的神经网络,然后重新使用其较低层。 这样就可以仅使用很少的训练数据来训练高性能模型,因为您的神经网络不必学习所有的低级特征;它将重新使用现有网络学习的特征检测器。
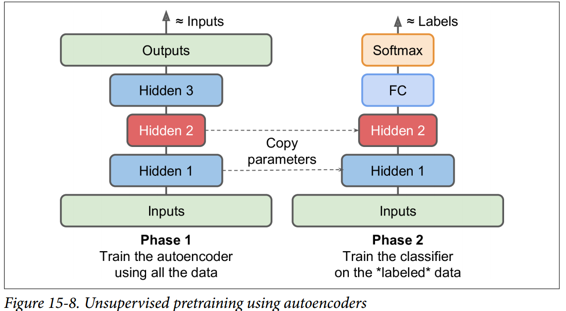
同样,如果您有一个大型数据集,但大多数数据集未标记,您可以先使用所有数据训练栈式自编码器,然后重新使用较低层为实际任务创建一个神经网络,并使用标记数据对其进行训练。 例如,图 15-8 显示了如何使用栈式自编码器为分类神经网络执行无监督预训练。 正如前面讨论过的,栈式自编码器本身通常每次都会训练一个自编码器。 在训练分类器时,如果您确实没有太多标记的训练数据,则可能需要冻结预训练层(至少是较低层)。
这种情况实际上很常见,因为构建一个大型的无标签数据集通常很便宜(例如,一个简单的脚本可以从互联网上下载数百万张图像),但只能由人类可靠地标记它们(例如,将图像分类为可爱或不可爱)。 标记实例是耗时且昂贵的,因此只有几千个标记实例是很常见的。
正如我们前面所讨论的那样,当前深度学习海啸的触发因素之一是 Geoffrey Hinton 等人在 2006 年的发现,深度神经网络可以以无监督的方式进行预训练。 他们使用受限玻尔兹曼机器(见附录 E),但在 2007 年 Yoshua Bengio 等人表明自编码器也起作用。
TensorFlow 的实现没有什么特别之处:只需使用所有训练数据训练自编码器,然后重用其编码器层以创建一个新的神经网络(有关如何重用预训练层的更多详细信息,请参阅第 11 章或查看 Jupyte notebooks 中的代码示例)。
到目前为止,为了强制自编码器学习有趣的特性,我们限制了编码层的大小,使其不够完善。 实际上可以使用许多其他类型的约束,包括允许编码层与输入一样大或甚至更大的约束,导致过度完成的自编码器。 现在我们来看看其中的一些方法。
